
html解析器,HTML解析器概述
 admin
adminHTML解析器是用于将HTML文档转换为可操作的树状结构的东西。这种结构一般被称为DOM(文档目标模型),它答应开发者以编程办法遍历、修正和查询HTML文档的内容。
HTML解析器的首要效果包含:
1. 解析HTML文档:解析器将HTML文档转换为DOM树,以便程序能够了解其结构和内容。2. 过错处理:HTML解析器一般能够处理HTML文档中的过错和不良格局,保证解析进程的鲁棒性。3. 供给API:解析器供给API,答应开发者拜访DOM树中的元素,并履行各种操作,如读取特点、修正内容、增加或删去元素等。
常用的HTML解析器包含:
Python中的BeautifulSoup:这是一个十分盛行的HTML和XML解析器,它供给了一个简略易用的API来解析HTML文档。 JavaScript中的DOM解析器:浏览器内置的DOM解析器,用于解析网页中的HTML和CSS,并供给操作DOM的API。 Java中的Jsoup:这是一个Java库,用于解析HTML文档,并供给了一个简略易用的API来操作DOM。
挑选哪种HTML解析器取决于详细的使用场景和编程言语。关于Python开发者来说,BeautifulSoup是一个很好的挑选,由于它简略易用且功能强大。关于Web开发来说,JavaScript的DOM解析器是必不可少的。
深化解析 HTML 解析器:技能原理与使用实践
HTML(HyperText Markup Language)是构建网页的根底,而HTML解析器则是解析HTML文档的要害东西。HTML解析器能够将HTML文档转换成可操作的文档目标模型(DOM),使得开发者能够方便地拜访和修正网页内容。本文将深化探讨HTML解析器的技能原理,并介绍其在实践使用中的实践办法。
HTML解析器概述
HTML解析器是一种软件东西,用于解析HTML文档并构建DOM树。DOM树是一种树形结构,它将HTML文档中的元素、特点和文本内容以节点的办法组织起来。常见的HTML解析器有Jsoup、BeautifulSoup等。
HTML解析器的作业原理
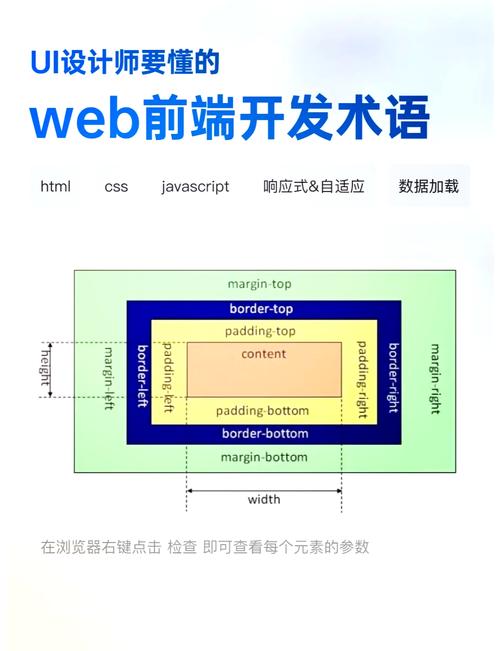
HTML解析器的作业原理首要包含以下几个过程:
解析HTML文档:解析器首要读取HTML文档,并将其内容存储在内存中。
构建DOM树:解析器依据HTML文档的结构,构建DOM树。DOM树中的每个节点都对应HTML文档中的一个元素。
遍历DOM树:开发者能够经过遍历DOM树来拜访和修正网页内容。
履行操作:依据需要,开发者能够对DOM树进行各种操作,如增加、删去、修正节点等。
Jsoup:Java的HTML解析器
// 解析URL
Document doc = Jsoup.connect(\
相关文章
-
html5魔塔,魔塔游戏简介
基本信息HTML5魔塔是一款经典的2D战略类固定数值RPG游戏,玩家将扮演一个王国的勇士,前往远方的魔塔,挽救公主并探...

-
html文档结构,```html 网页标题
HTML文档结构一般遵从以下形式,包括文档类型声明(Doctype)、HTML元素、头部(Head)和主体(Body)部...

-
jquery获取元素, 什么是jQuery获取元素?
2.$:你能够直接传递一个DOM元素给jQuery。例如,`$`回来文档目标。3.$:你能够传递HTM...

-
在线运转html,什么是HTML?
我无法直接运转HTML代码,由于我是一个文本和代码生成的AI。可是,我能够供给HTML代码,你能够在任何支撑HTML的浏...

-
html教程
根底学习1.了解HTML的根本结构:HTML文档由``声明开端,接着是``元素,它包括``和``两部分。...

-
css 文本缩进, 什么是文本缩进
CSS中设置文本缩进能够运用`textindent`特点。这个特点界说了文本块首行的缩进量。语法```csste...

-
html躲藏div,```htmlHide Div Example .hiddendiv { display: none; / Hide the div / } .visiblediv { visibility: hidden; / Hide the div but keep its space / }
在HTML中,你能够运用CSS来躲藏一个``元素。有几种办法能够完成这一作用,包含设置元素的`display`特点为`n...
-
html静态网页代码模板,html静态网页模板
当然能够,下面是一个简略的HTML静态网页代码模板:```html我的第一个网页欢迎来到...