
机器学习模型挑选,关键进程与最佳实践
 admin
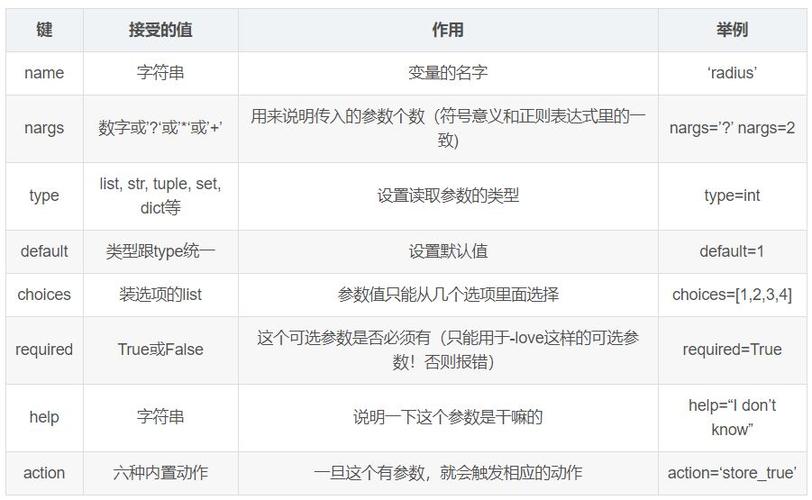
admin1. 线性回归:适用于猜测接连值,如房价猜测。2. 逻辑回归:适用于二分类问题,如垃圾邮件检测。3. 决策树:适用于分类和回归问题,易于了解,但或许过拟合。4. 随机森林:由多个决策树组成,适用于分类和回归问题,鲁棒性较好。5. 支撑向量机(SVM):适用于高维数据,如文本分类。6. 聚类算法(如Kmeans):适用于无监督学习,如客户细分。7. 神经网络:适用于杂乱问题,如图像识别、自然语言处理。
挑选模型时,能够遵从以下进程:
1. 了解问题类型和数据特色。2. 依据问题类型挑选适宜的模型类型。3. 在多个模型中进行比较,挑选功能最优的模型。4. 考虑模型杂乱性和练习时刻,挑选适宜资源约束的模型。5. 运用穿插验证等办法评价模型功能,并进行调优。
总归,挑选机器学习模型是一个需求归纳考虑多个要素的进程。
机器学习模型挑选:关键进程与最佳实践
在机器学习项目中,挑选适宜的模型是至关重要的。一个适宜的模型不只能够进步猜测的准确性,还能优化核算资源,降低成本。本文将讨论机器学习模型挑选的关键进程和最佳实践。
一、清晰问题与数据了解

在进行模型挑选之前,首先要清晰问题的类型,如回归、分类或聚类等。接着,对数据进行深化了解,包含数据的散布、特征和噪声等。这一进程有助于确认适宜的模型类型和预处理办法。
二、数据预处理
数据预处理是机器学习模型挑选的重要环节。它包含数据清洗、特征工程、数据标准化等。预处理后的数据将直接影响模型的功能。
数据清洗:去除缺失值、异常值和重复值。
特征工程:创立新的特征或转化现有特征,以进步模型的猜测才能。
数据标准化:将数据缩放到相同的标准,防止某些特征对模型的影响过大。
三、挑选适宜的模型
线性回归:适用于回归问题,当数据呈线性关系时作用较好。
逻辑回归:适用于二分类问题,经过Sigmoid函数将猜测值转化为概率。
决策树:适用于回归和分类问题,易于了解和解说。
随机森林:适用于回归和分类问题,具有较好的泛化才能。
支撑向量机(SVM):适用于回归和分类问题,适用于高维数据。
神经网络:适用于杂乱问题,具有强壮的非线性建模才能。
四、模型评价与调优
评价目标:准确率、召回率、F1值、均方误差等。
穿插验证:经过将数据集划分为练习集和测验集,评价模型的泛化才能。
网格查找:经过遍历参数空间,寻觅最优参数组合。
贝叶斯优化:依据贝叶斯计算原理,寻觅最优参数组合。
五、模型布置与监控
模型布置:将模型集成到使用程序中,完成实时猜测。
监控:实时监控模型功能,及时发现异常并采纳办法。
模型更新:依据新数据或事务需求,定时更新模型。
机器学习模型挑选是一个杂乱的进程,需求归纳考虑问题类型、数据特色、模型功能和实践使用需求。经过遵从上述关键进程和最佳实践,能够进步模型挑选的成功率,为机器学习项目带来更好的作用。
相关文章
-
cdn机器学习,进步内容分发网络功能的新篇章
CDN(内容分发网络)与机器学习的结合正在逐渐改动内容分发的智能化水平。以下是CDN与机器学习结合的首要运用和技能原理:...

-
ai是什么元素,引领未来开展的中心元素
AI(人工智能)本身不是一种元素,它是一种依据计算机科学和认知科学的技能范畴,旨在创立可以模仿、延伸和扩展人类智能的理论...

-
cdr转ai,轻松完结文件格局的转化与兼容性进步
CDR和AI都是矢量图形修改软件,它们各自有共同的文件格局。CDR是CorelDRAW的文件格局,而AI是Ad...

-
机器学习 聚类,什么是聚类剖析?
聚类(Clustering)是机器学习范畴中的一种无监督学习技能,首要用于将数据会集的方针依照类似性分组。聚类算法的方针...

-
AI教程, 二、Stable Diffusion简介
AdobeIllustrator教程1.100集(全)从零开始学illustrator软件根底(2024新手入门有...

-
机器学习实战 数据,数据预处理与模型构建全解析
1.《机器学习实战:依据ScikitLearn、Keras和TensorFlow》第3版资源下载:该库房供给了...

-
ai是什么意思,什么是AI?
AI是人工智能的缩写,英文全称为ArtificialIntelligence。人工智能是指由人制造出来的体系所...

-
归纳ai大模型,技能革新与工业革新的引擎
归纳AI大模型是指具有广泛功用和使用砛nAI大模型:技能革新与工业革新的引擎一、AI大模型:界说与中心要素AI大模型...
