
机器学习数据剖析项目,从数据预处理到模型评价
 admin
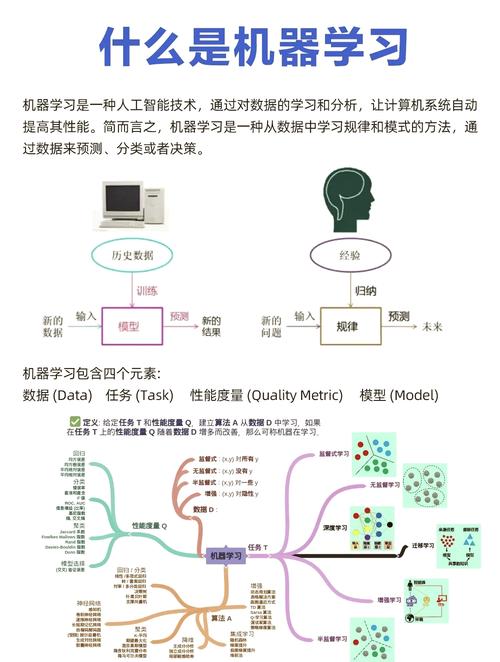
admin机器学习数据剖析项目一般包含以下几个进程:
1. 问题界说:清晰项目方针,确认需求处理的问题。这包含了解事务需求、清晰项目规模和预期作用。
2. 数据搜集:依据问题界说,搜集相关数据。数据能够来自多种来历,如数据库、API、文件等。
3. 数据预处理:对搜集到的数据进行清洗、转化和归一化。这包含处理缺失值、异常值、重复数据等。
4. 特征工程:从原始数据中提取或创立新的特征,以增强模型的学习才能。
5. 模型挑选:依据问题类型(如分类、回归、聚类等)挑选适宜的机器学习模型。
6. 模型练习:运用练习数据集对模型进行练习,调整模型参数以优化功能。
7. 模型评价:运用验证数据集或测试数据集评价模型的功能,包含精确率、召回率、F1分数等方针。
8. 模型布置:将练习好的模型布置到出产环境中,以便在实践运用中运用。
9. 监控和保护:对布置的模型进行监控,保证其功能安稳。依据需求进行模型更新或从头练习。
在整个项目进程中,需求运用各种东西和技能,如Python、R、SQL、数据可视化东西、机器学习库(如scikitlearn、TensorFlow、PyTorch)等。此外,还需求考虑数据隐私、安全性和合规性等问题。
机器学习数据剖析项目实战:从数据预处理到模型评价
跟着大数据年代的到来,机器学习在数据剖析中的运用越来越广泛。本文将具体介绍一个机器学习数据剖析项目的实战进程,包含数据预处理、特征工程、模型挑选、练习与评价等关键进程。
一、项目布景与方针
项目布景:某电商渠道期望经过剖析用户购买行为数据,猜测用户是否会购买某款产品,然后完成精准营销。
项目方针:构建一个机器学习模型,能够精确猜测用户购买行为,进步营销作用。
二、数据预处理
数据预处理是机器学习项目中的关键进程,它包含数据清洗、数据转化和数据集成等。
1. 数据清洗
在数据清洗阶段,咱们需求处理缺失值、异常值和重复值等问题。
(1)缺失值处理:关于缺失值,咱们能够选用填充、删去或插值等办法进行处理。
(2)异常值处理:经过可视化或计算办法辨认异常值,并对其进行处理。
(3)重复值处理:删去重复数据,防止模型过拟合。
2. 数据转化
数据转化包含数值型数据转化和类别型数据转化。
(1)数值型数据转化:对数值型数据进行标准化、归一化或离散化处理。
3. 数据集成
将预处理后的数据集进行整合,为后续建模做准备。
三、特征工程

特征工程是进步模型功能的关键环节,它包含特征挑选、特征提取和特征组合等。
1. 特征挑选
经过计算办法、模型挑选或递归特征消除等办法,挑选对模型猜测有重要影响的特征。
2. 特征提取
从原始数据中提取新的特征,进步模型的猜测才能。
3. 特征组合
将多个特征组合成新的特征,以增强模型的猜测才能。
四、模型挑选与练习

依据项目需求和数据特色,挑选适宜的机器学习模型,并进行练习。
1. 模型挑选
依据项目布景和方针,挑选适宜的机器学习模型,如逻辑回归、决策树、支撑向量机、随机森林等。
2. 模型练习
运用预处理后的数据集对模型进行练习,调整模型参数,进步模型功能。
五、模型评价与优化
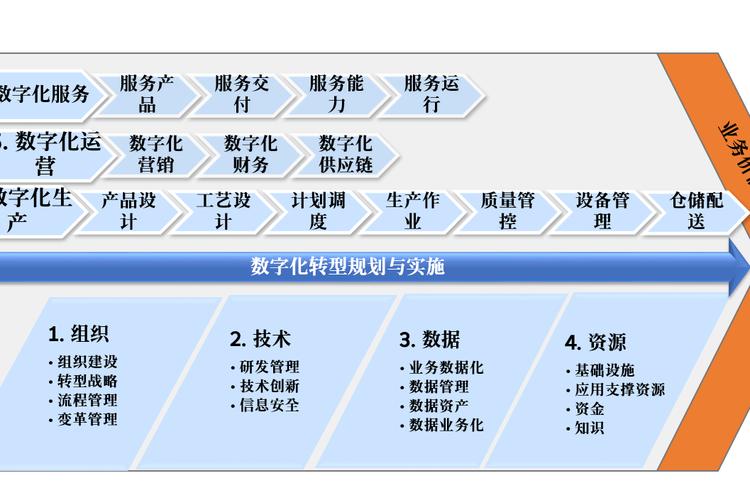
对练习好的模型进行评价,并依据评价成果进行优化。
1. 模型评价
运用穿插验证、混杂矩阵、ROC曲线等办法对模型进行评价。
2. 模型优化
依据评价成果,调整模型参数或测验其他模型,以进步模型功能。
本文具体介绍了机器学习数据剖析项目的实战进程,从数据预处理到模型评价,每个进程都进行了具体论述。经过实践操作,咱们能够更好地了解机器学习在数据剖析中的运用,为后续项目供给参阅。
相关文章
-
ai归纳使用,推进工业革新与立异开展的新引擎
AI归纳使用是指将人工智能技能使用于各个范畴,以处理实际问题并进步功率。以下是几个AI归纳使用范畴的比如:1.医疗健康...

-
AI写ppt,高效与构思的完美结合
当然能够!我能够协助你编撰PPT的内容。请告诉我你需求关于什么主题的PPT,以及你期望绵亘哪些详细信息或要害。我会依据你...

-
股票猜测机器学习,技能革新与未来展望
股票猜测是一个杂乱的问题,由于它涉及到很多的变量和不确定性。机器学习能够供给一种办法来剖析前史数据,并从中提取有用的形式...

-
斯坦福机器学习证书,在线学习,成果未来
假如你想取得斯坦福大学的机器学习证书,能够经过Coursera渠道上的“机器学习专项课程”来完结。这个课程由斯坦福大学和...

-
ai归纳原料画,探究数字艺术的新境地
1.AIACG绘画网站:这是一个完全免费的AI绘画网站,供给了很多的AI绘画模型,绵亘二次元、插画和美人大模型,...

-
机器学习模型怎样跑,从建立到优化
机器学习模型一般绵亘以下几个进程来运转:1.数据预备:首要需求搜集和预备数据,这绵亘数据清洗、数据转化和数据归一化等。...

-
amd做机器学习,AMD在机器学习范畴的立异与打破
1.AMDRyzenAI软件:RyzenAI软件:这款软件可以协助用户在AIPC上轻松构建和布置机...

-
AI归纳训练,敞开智能年代的学习新篇章
1.AIGC学院:供给全面的AI职业证书及训练课程,绵亘人工智能根底常识、中心技能及使用范畴。课程绵亘免费和付...
