
rf机器学习,随机森林算法的运用与优势
 admin
adminRF 机器学习
RF(随机森林)是一种强壮的机器学习算法,广泛运用于分类、回归和特征挑选等使命。RF 经过构建多个决策树并对它们的成果进行集成,以削减过拟合和进步模型泛化才能。
RF 的作业原理
1. 构建多棵决策树: RF 首要构建多棵决策树,每棵树都依据原始数据集的一个随机子集。子集的挑选可以经过自助采样法(bootstrap sampling)完成,即从原始数据会集有放回地随机抽取样本。2. 随机特征挑选: 在构建每棵树时,RF 会从一切特征中随机挑选一部分特征,用于区分节点。这样可以添加模型的多样性,并削减对单个特征的依靠。3. 树的成长: 每棵树都依据选定的特征进行割裂,直到到达预设的深度或满意其他中止条件。4. 集成猜测: 对一切树的猜测成果进行集成,得到终究的猜测成果。集成方法可以是大都投票法(分类使命)或均匀法(回归使命)。
RF 的优势
强壮的泛化才能: 经过集成多棵树,RF 可以有用地削减过拟合,进步模型的泛化才能。 鲁棒性: RF 对反常值和噪声不灵敏,可以处理缺失数据。 特征挑选: RF 可以用于特征挑选,识别对猜测成果奉献最大的特征。 易于解说: 比较于其他杂乱的机器学习算法,RF 的成果更简单解说。
RF 的运用
分类: RF 可以用于各种分类使命,例如垃圾邮件过滤、疾病诊断等。 回归: RF 可以用于各种回归使命,例如房价猜测、股票价格猜测等。 特征挑选: RF 可以用于识别对猜测成果奉献最大的特征,然后简化模型并进步效率。 反常检测: RF 可以用于检测数据会集的反常值。
RF 的参数
树的数量: 树的数量越多,模型的泛化才能越强,但计算成本也越高。 树的最大深度: 树的深度越大,模型越杂乱,但也更简单过拟合。 特征的数量: 在每棵树中挑选的特征数量越多,模型的多样性越高,但也更简单过拟合。
RF 的完成
RF 可以运用多种编程言语完成,例如 Python、R 和 MATLAB。常用的 Python 库包含 scikitlearn 和 TensorFlow。
RF 是一种强壮的机器学习算法,具有强壮的泛化才能、鲁棒性和特征挑选才能。它广泛运用于各种机器学习使命,是机器学习范畴的重要东西之一。
期望以上信息能帮助您更好地了解 RF 机器学习算法。假如您有任何其他问题,请随时发问。
深化解析RF机器学习:随机森林算法的运用与优势
跟着大数据年代的到来,机器学习技能在各个范畴得到了广泛运用。其间,随机森林(Random Forest,RF)算法因其强壮的猜测才能和杰出的泛化功能,成为机器学习范畴的一大亮点。本文将深化解析RF算法,讨论其在实践运用中的优势。
一、什么是随机森林算法?
随机森林算法是一种依据决策树的集成学习方法。它经过构建多个决策树,并对它们的猜测成果进行投票或均匀,然后得到终究的猜测成果。与单个决策树比较,随机森林算法具有以下特色:
强泛化才能:随机森林算法可以有用下降过拟合现象,进步模型的泛化功能。
鲁棒性:随机森林算法对噪声数据具有较强的鲁棒性,可以处理大规模数据集。
可解说性:随机森林算法可以评价特征的重要性,有助于了解模型的猜测进程。
二、随机森林算法的作业原理
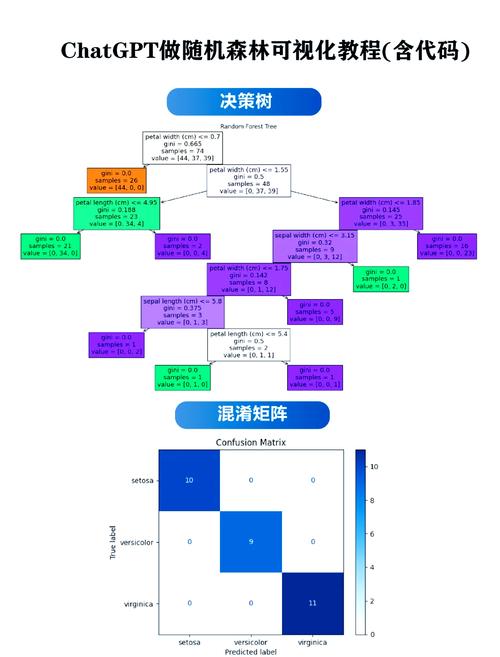
随机森林算法的作业原理首要包含以下进程:
从原始数据会集随机抽取必定数量的样本,构建多个决策树。
在每个决策树的构建进程中,随机挑选部分特征进行区分,以添加模型的多样性。
对每个决策树的猜测成果进行投票或均匀,得到终究的猜测成果。
三、随机森林算法的运用场景
随机森林算法在各个范畴都有广泛的运用,以下罗列一些常见的运用场景:
金融范畴:危险评价、信誉评分、股票猜测等。
医疗范畴:疾病诊断、药物研制、患者预后等。
生物信息学:基因功能猜测、蛋白质结构猜测等。
自然言语处理:文本分类、情感剖析等。
四、随机森林算法的优势
随机森林算法具有以下优势:
强壮的猜测才能:随机森林算法可以处理大规模数据集,并具有较高的猜测精度。
杰出的泛化功能:随机森林算法可以有用下降过拟合现象,进步模型的泛化功能。
可解说性:随机森林算法可以评价特征的重要性,有助于了解模型的猜测进程。
鲁棒性:随机森林算法对噪声数据具有较强的鲁棒性,可以处理大规模数据集。
随机森林算法作为一种强壮的机器学习算法,在各个范畴都有广泛的运用。其强壮的猜测才能、杰出的泛化功能和可解说性等特色,使其成为机器学习范畴的一大亮点。跟着技能的不断发展,信任随机森林算法将在更多范畴发挥重要作用。
相关文章
-
ai识图,革新视觉辨认的未来
1.图画分类:将图画分类到不同的类别中,例如辨认图画中的物体、场景、情感等。2.方针检测:在图画中检测并定位特定的物...

-
巴黎归纳理工ai,AI范畴的前锋力气
巴黎归纳理工学院:AI范畴的前锋力气巴黎归纳理工学院(EcolePolytechnique),简称X,作为法国甚至欧洲...

-
ai se 归纳,推进工业革新与立异
AISE(AIforSoftwareEngineering,人工智能辅佐软件工程)是指将人工智能技能运用于软件工...

-
机器学习大牛,那些改动世界的“大牛”们
1.MichaelI.Jordan:他是加州大学伯克利分校的教授,担任计算人工智能试验室(SAIL)主任和...

-
机器学习的进程,机器学习进程概述
机器学习是一个迭代的进程,它包含以下首要进程:1.界说问题:明晰你要处理的问题是什么。这包含确认方针变量(猜测或分类的...

-
ai资料,立异内容创造的得力助手
1.爱给网供给多种格局的矢量图资料,包含AI、EPS、CDR、SVG等,适用于平面规划、UI、海报、PPT等砛...

-
机器学习程序,从入门到实践
当然,我可以协助你了解机器学习程序的基本概念。机器学习是一种人工智能技能,它答应核算机从数据中学习并做出决议计划或猜测,...

-
机器学习与大数据实战,从理论到使用的跨过
机器学习与大数据实战是当今科技范畴中十分抢手的两个方向。它们彼此相关,相得益彰,一起推进着各行各业的智能化转型。以下是对...
