
机器学习实战代码,从数据预处理到模型评价
 admin
admin示例数据X = np.array, , , , qwe2qwe2y = np.arrayqwe2
示例数据X = np.array, , , , qwe2qwe2y = np.arrayqwe2
3. 决策树:用于分类和回归使命。```pythonfrom sklearn.tree import DecisionTreeClassifier
示例数据X = np.array, , , , qwe2qwe2y = np.arrayqwe2
4. 支撑向量机(SVM):用于分类和回归使命。```pythonfrom sklearn.svm import SVC
示例数据X = np.array, , , , qwe2qwe2y = np.arrayqwe2
这些代码示例仅用于演示意图,您或许需求根据您的详细需求进行调整和优化。假如您有特定的问题或需求,请告诉我,我会极力帮助您。
机器学习实战代码:从数据预处理到模型评价
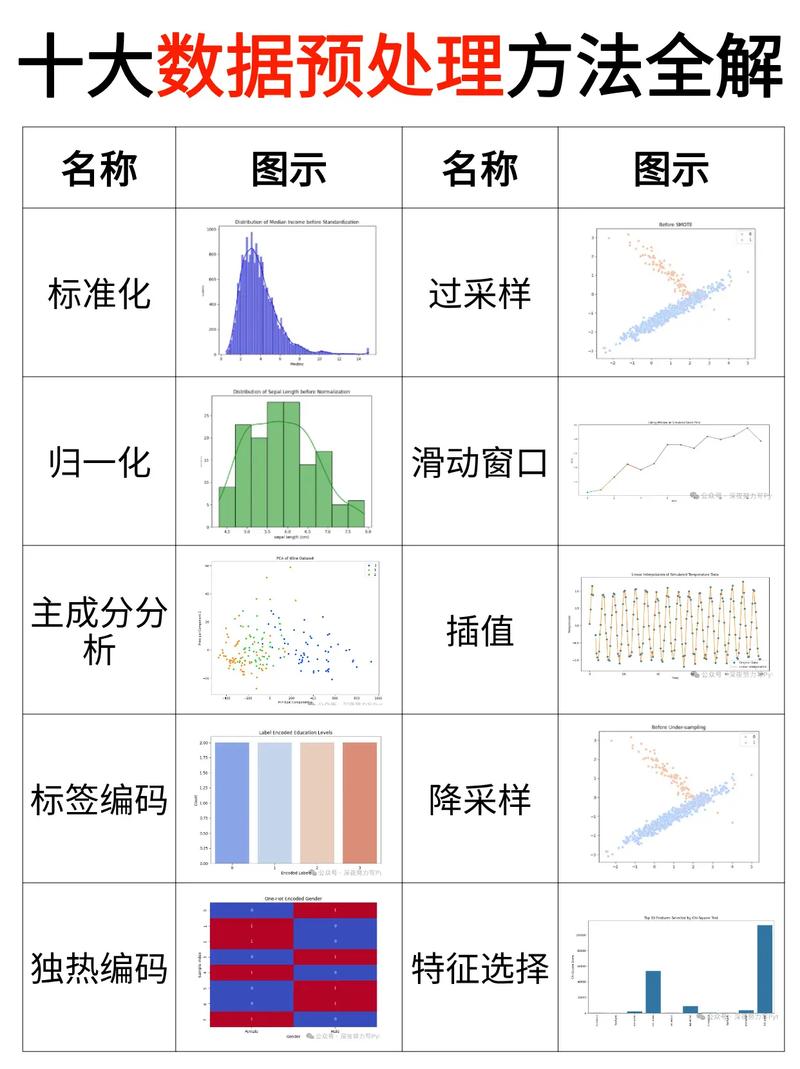
一、环境预备

在进行机器学习实战之前,咱们需求预备以下环境:
Python 3.x 版别
NumPy、Pandas、Scikit-learn、Matplotlib 等库
适宜的数据集
二、数据预处理
数据预处理是机器学习流程中的关键进程,它包含数据清洗、数据转化和数据归一化等。
2.1 数据清洗
数据清洗的首要意图是去除数据中的噪声和不完好信息。以下是一个简略的数据清洗示例代码:
```python
import pandas as pd
加载数据集
data = pd.read_csv('data.csv')
删去缺失值
data.dropna(inplace=True)
删去重复行
data.drop_duplicates(inplace=True)
删去无用列
data.drop(['unnecessary_column'], axis=1, inplace=True)
2.2 数据转化
数据转化包含将分类数据转化为数值数据、处理不平衡数据等。以下是一个将分类数据转化为数值数据的示例代码:
```python
from sklearn.preprocessing import LabelEncoder
创立编码器目标
label_encoder = LabelEncoder()
对分类数据进行编码
data['encoded_column'] = label_encoder.fit_transform(data['category_column'])
2.3 数据归一化
数据归一化是将数据缩放到一个固定规模,如 [0, 1] 或 [-1, 1]。以下是一个数据归一化的示例代码:
```python
from sklearn.preprocessing import MinMaxScaler
创立归一化器目标
scaler = MinMaxScaler()
对数据进行归一化
data_scaled = scaler.fit_transform(data)
三、模型挑选与练习
在完结数据预处理后,咱们需求挑选适宜的模型进行练习。以下是一个运用决策树模型进行练习的示例代码:
```python
from sklearn.tree import DecisionTreeClassifier
创立决策树模型目标
练习模型
四、模型评价
模型评价是衡量模型功能的重要进程。以下是一个运用准确率、召回率和F1分数评价决策树模型的示例代码:
```python
from sklearn.metrics import accuracy_score, recall_score, f1_score
猜测测验集
核算准确率、召回率和F1分数
accuracy = accuracy_score(data_scaled[:, -1], predictions)
recall = recall_score(data_scaled[:, -1], predictions)
f1 = f1_score(data_scaled[:, -1], predictions)
print(f'Accuracy: {accuracy}')
print(f'Recall: {recall}')
print(f'F1 Score: {f1}')
本文经过一个完好的机器学习实战代码示例,展现了从数据预处理到模型评价的整个进程。经过实际操作,读者能够更好地了解机器学习的基本概念和流程,为后续的学习和使用打下坚实的根底。
相关文章
-
ai家具归纳城,未来家居购物的新趋势
AI家居官方商城供给一站式的全屋定制家具服务,包含全体衣柜、榻榻米、电视柜、餐边柜、书橱、玄关鞋柜、吧台酒柜等全屋家具定...

-
儿童学习编程机器人,敞开未来智能之门
1.玛塔编程机器人:特色:玛塔编程机器人适宜4到9岁的孩子,选用无屏幕什物编程,经过编程块来操控机器人,规划对...

-
ai全称,人工智能的全面知道
AI的全称是“人工智能”(ArtificialIntelligence),它是指由人制造出来的体系所表现出来的智能。人...

-
ai著作归纳出现,技能与艺术的完美交融
1.广告范畴:麦当劳与AIGC协作:2023年4月,麦当劳推出了一组由AI与顾客、粉丝一起发明的宣扬广告,这些...

-
机器学习书面考试,全面解析常见题型与应对战略
基础知识1.界说与概念:如监督学习、无监督学习、强化学习等。2.模型与算法:如线性回归、决策树、支撑向量机、神经网...

-
机器学习 豆瓣,机器学习在豆瓣电影引荐体系中的运用
1.《机器学习》:作者:周志华简介:这本书是机器学习范畴的入门教材,涵盖了机器学习根底知识的各个方面,...

-
深度学习和机器学习的差异,深度学习与机器学习的差异
深度学习和机器学习是人工智能范畴的两个重要分支,它们之间既有联络也有差异。以下是它们的首要差异:1.界说和概念:...
-
gam机器学习,从原理到运用
GAM(广义加性模型)是一种机器学习模型,它经过组合一系列滑润函数来猜测呼应变量。这些滑润函数能够对错参数的,也能够是参...
