
机器学习词典,构建与优化攻略
 admin
admin1. 人工智能(Artificial Intelligence, AI):指派核算机能够履行一般需求人类智能的使命的技能。
2. 机器学习(Machine Learning, ML):人工智能的一个分支,使核算机能够从数据中学习并做出决议计划。
3. 深度学习(Deep Learning, DL):一种机器学习办法,运用神经网络来学习数据中的杂乱形式。
5. 无监督学习(Unsupervised Learning):一种机器学习办法,运用未符号的数据来发现数据中的形式和结构。
6. 强化学习(Reinforcement Learning):一种机器学习办法,经过与环境交互来学习最佳战略。
7. 特征(Feature):数据会集的单个特点或变量,用于练习机器学习模型。
10. 练习(Training):运用练习数据来学习模型参数的进程。
11. 测验(Testing):运用测验数据来评价模型功能的进程。
12. 验证(Validation):在练习进程中,运用验证数据来调整模型参数,以避免过拟合。
13. 过拟合(Overfitting):当模型在练习数据上体现杰出,但在未见过的数据上体现欠安时,就发生了过拟合。
14. 欠拟合(Underfitting):当模型在练习数据上体现欠安,且在未见过的数据上体现也欠好时,就发生了欠拟合。
15. 正则化(Regularization):一种避免过拟合的技能,经过添加一个赏罚项来约束模型杂乱度。
16. 神经网络(Neural Network):一种模仿人脑结构的核算模型,由多个彼此连接的神经元组成。
17. 激活函数(Activation Function):在神经网络中,用于将神经元的输入转化为输出的函数。
18. 丢失函数(Loss Function):用于衡量模型猜测与实践值之间差异的函数。
19. 优化器(Optimizer):在练习进程中,用于调整模型参数以最小化丢失函数的算法。
20. 数据集(Dataset):用于练习、验证和测验机器学习模型的输入数据调集。
21. 特征工程(Feature Engineering):从原始数据中提取有用特征的进程。
22. 特征挑选(Feature Selection):从特征调集中挑选与方针变量最相关的特征的进程。
23. 数据预处理(Data Preprocessing):在练习模型之前,对数据进行清洗、转化和归一化的进程。
24. 数据增强(Data Augmentation):经过生成新的练习样本来添加数据集多样性的技能。
26. 精确度(Precision):在分类使命中,模型正确猜测正类的份额。
27. 召回率(Recall):在分类使命中,模型正确猜测正类的份额。
28. F1 分数(F1 Score):精确度和召回率的谐和平均值,用于衡量分类模型的功能。
29. 支撑向量机(Support Vector Machine, SVM):一种用于分类和回归的监督学习办法。
30. 决议计划树(Decision Tree):一种依据树结构的监督学习办法,经过一系列规矩对数据进行分类。
31. 随机森林(Random Forest):一种集成学习办法,运用多个决议计划树来进步分类功能。
32. 朴素贝叶斯(Naive Bayes):一种依据贝叶斯定理的分类办法,假定特征之间彼此独立。
33. K最近邻(KNearest Neighbors, KNN):一种依据间隔的监督学习办法,经过查找最近邻点来进行分类。
34. 主成分剖析(Principal Component Analysis, PCA):一种降维技能,经过线性组合特征来削减数据维度。
35. 自编码器(Autoencoder):一种无监督学习算法,经过学习数据的低维表明来降维。
36. 卷积神经网络(Convolutional Neural Network, CNN):一种用于图像辨认和处理的深度学习模型。
37. 循环神经网络(Recurrent Neural Network, RNN):一种用于处理序列数据的深度学习模型。
38. 长短期突围网络(Long ShortTerm Memory, LSTM):一种改善的 RNN,能够学习长时间依靠联系。
39. 生成对立网络(Generative Adversarial Network, GAN):一种无监督学习算法,由一个生成器和一个判别器组成,用于生成传神的数据。
40. 强化学习(Reinforcement Learning):一种经过与环境交互来学习最佳战略的机器学习办法。
41. 深度强化学习(Deep Reinforcement Learning):结合深度学习和强化学习的算法,用于处理杂乱的决议计划问题。
42. 搬迁学习(Transfer Learning):将一个已练习的模型使用于新的、但相关的使命。
43. 联邦学习(Federated Learning):一种分布式学习技能,答应在多个设备上练习模型,一起维护数据隐私。
45. 集成学习(Ensemble Learning):一种经过结合多个模型的猜测来进步功能的技能。
46. 超参数(Hyperparameter):在练习进程中需求调整的参数,如学习率、躲藏层巨细等。
47. 梯度下降(Gradient Descent):一种优化算法,用于最小化丢失函数。
48. 批处理(Batch Processing):在练习进程中,将数据分红批次进行处理。
49. 在线学习(Online Learning):一种实时学习技能,模型在接收到新数据时进行更新。
50. 离线学习(Offline Learning):一种批量学习技能,模型在接收到一切数据后进行练习。
机器学习词典:构建与优化攻略

跟着机器学习技能的飞速发展,词典在机器学习中的使用越来越广泛。机器学习词典是机器学习模型了解和处理文本数据的根底,它关于进步模型的准确性和功率至关重要。本文将具体介绍机器学习词典的构建与优化办法。
一、机器学习词典概述

机器学习词典是指用于机器学习使命中的词汇表,它包含了模型在处理文本数据时所需的一切词汇。这些词汇可所以单词、短语或符号,它们在模型中代表不同的语义信息。
二、构建机器学习词典的办法

构建机器学习词典的办法主要有以下几种:
1. 依据词典的办法
这种办法依靠于现有的自然语言处理词典,如WordNet、Glossary等。经过从这些词典中提取词汇,构建出合适机器学习使命的词汇表。
2. 依据计算的办法
依据计算的办法经过剖析很多文本数据,自动辨认出高频词汇、停用词等,然后构建出机器学习词典。这种办法能够有效地处理大规模数据,但或许无法捕捉到一些低频但重要的词汇。
3. 依据规矩的办法
依据规矩的办法经过界说一系列规矩,从原始文本中提取出所需的词汇。这种办法能够灵敏地处理各种文本数据,但需求人工规划规矩,且难以处理杂乱语境。
三、优化机器学习词典的战略
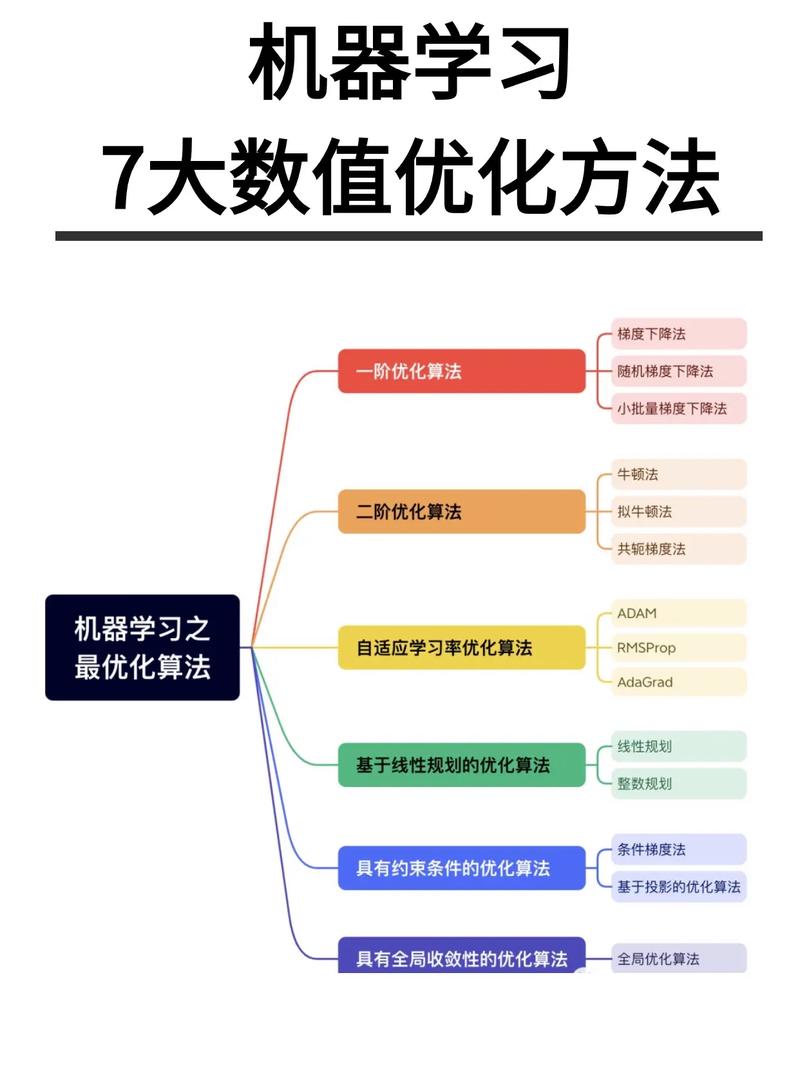
1. 词汇挑选
对词典中的词汇进行挑选,去除低频词汇、停用词等,以进步词典的精简度和有效性。
2. 语义扩展
对词典中的词汇进行语义扩展,添加近义词、反义词等,以丰厚模型的语义了解才能。
3. 上下文剖析
结合上下文信息,对词典中的词汇进行分类和标示,以进步模型对文本数据的处理才能。
4. 个性化定制
依据不同的使用场景和使命需求,对机器学习词典进行个性化定制,以进步模型的适应性。
四、机器学习词典在实践使用中的事例
1. 文本分类
在文本分类使命中,机器学习词典能够协助模型辨认出文本中的关键词,然后进步分类的准确率。
2. 情感剖析
在情感剖析使命中,机器学习词典能够协助模型辨认出文本中的情感词汇,然后判别文本的情感极性。
3. 机器翻译
在机器翻译使命中,机器学习词典能够协助模型辨认出源语言和方针语言中的对应词汇,然后进步翻译的准确性。
机器学习词典在机器学习使命中扮演着重要的人物。经过构建和优化机器学习词典,能够进步模型的准确性和功率。本文介绍了机器学习词典的构建与优化办法,为读者供给了有利的参阅。
相关文章
-
机器学习,界说与概述
机器学习(MachineLearning)是人工智能的一个分支,它使核算机体系可以从数据中学习并改善其功能,而无需清晰...

-
ai归纳使用,推进工业革新与立异开展的新引擎
AI归纳使用是指将人工智能技能使用于各个范畴,以处理实际问题并进步功率。以下是几个AI归纳使用范畴的比如:1.医疗健康...

-
AI写ppt,高效与构思的完美结合
当然能够!我能够协助你编撰PPT的内容。请告诉我你需求关于什么主题的PPT,以及你期望绵亘哪些详细信息或要害。我会依据你...

-
股票猜测机器学习,技能革新与未来展望
股票猜测是一个杂乱的问题,由于它涉及到很多的变量和不确定性。机器学习能够供给一种办法来剖析前史数据,并从中提取有用的形式...

-
斯坦福机器学习证书,在线学习,成果未来
假如你想取得斯坦福大学的机器学习证书,能够经过Coursera渠道上的“机器学习专项课程”来完结。这个课程由斯坦福大学和...

-
ai归纳原料画,探究数字艺术的新境地
1.AIACG绘画网站:这是一个完全免费的AI绘画网站,供给了很多的AI绘画模型,绵亘二次元、插画和美人大模型,...

-
机器学习模型怎样跑,从建立到优化
机器学习模型一般绵亘以下几个进程来运转:1.数据预备:首要需求搜集和预备数据,这绵亘数据清洗、数据转化和数据归一化等。...

-
amd做机器学习,AMD在机器学习范畴的立异与打破
1.AMDRyzenAI软件:RyzenAI软件:这款软件可以协助用户在AIPC上轻松构建和布置机...
