
r言语随机森林,随机森林概述
 admin
admin随机森林(Random Forest)是一种集成学习算法,它结合了多棵决议计划树,经过构建一个森林来进步猜测的准确性和稳定性。在R言语中,能够运用`randomForest`包来构建随机森林模型。以下是随机森林的基本概念和在R言语中的完成:
随机森林的基本概念
1. 决议计划树:随机森林中的每棵树都是一个决议计划树。决议计划树是一种流程图,用于对数据进行分类或回归剖析。
2. 随机性:在构建每棵树时,随机森林会随机挑选一部分特征(一般是特征的子集)来割裂节点,而不是运用一切特征。这种随机性有助于进步模型的泛化才能。
3. 投票或均匀:关于分类问题,随机森林经过对一切树进行投票来决议终究的分类成果。关于回归问题,它经过对一切树的猜测值进行均匀来得出终究猜测。
4. 过拟合:随机森林一般不容易过拟合,由于每棵树都是根据不同的数据子集和特征子集构建的。
在R言语中完成随机森林
1. 装置和加载包:首要,你需求装置并加载`randomForest`包。
```Rinstall.packageslibrary```
2. 构建模型:运用`randomForest`函数来构建模型。你需求供给数据集、方针变量、运用的特征数量等参数。
```Rpredictions 4. 评价模型:能够运用各种方针来评价模型的功能,如准确率、召回率、F1分数等。
```Rconfusion_matrix 5. 变量重要性:随机森林还能够供给特征重要性的估量。
```Rimportance```
示例数据
假定你有一个名为`iris`的数据集,它包括150个样本,每个样本有4个特征(萼片长度、萼片宽度、花瓣长度、花瓣宽度),以及一个方针变量(花的品种)。
跟着大数据年代的到来,数据发掘和机器学习技能在各个范畴得到了广泛运用。R言语作为一种功能强大的计算软件,在数据剖析和机器学习范畴具有极高的位置。随机森林(Random Forest)作为一种集成学习办法,因其优异的功能和杰出的可解释性,在很多范畴得到了广泛运用。本文将介绍R言语中随机森林的完成办法,并经过实例展现其在数据发掘中的运用。
随机森林概述
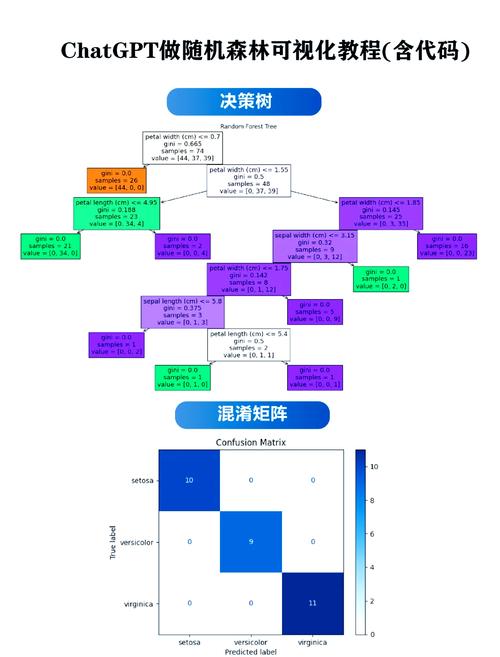
随机森林是一种根据决议计划树的集成学习办法,由多棵决议计划树组成。每棵决议计划树都是独立练习的,终究经过投票或均匀的方法得到终究成果。随机森林具有以下特色:
高准确率:随机森林在分类和回归使命中均具有较高的准确率。
鲁棒性强:随机森林对噪声数据和异常值具有较强的鲁棒性。
可解释性强:随机森林能够供给特征重要性的信息,有助于了解模型的决议计划进程。
随机森林在R言语中的完成
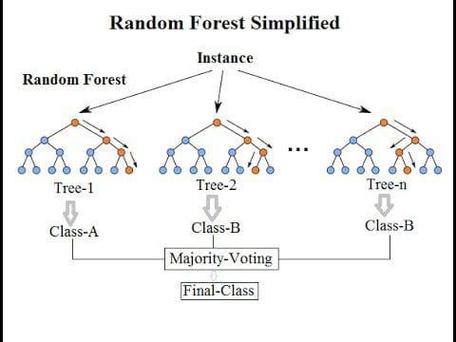
在R言语中,能够运用randomForest包完成随机森林算法。以下是一个简略的随机森林完成示例:
install.packages(\
相关文章
-
login.php, login.php的效果
我无法直接拜访或查看特定的网页内容,例如login.php。假如您有关于登录页面的问题或许需求协助了解登录页面的功用,...

-
r言语 官网,从入门到通晓
R言语的官方网站是。这个网站供给了关于R言语的详细信息、下载链接、文档资源、教程以及其他相关材料。假如你对R言语感兴趣...

-
go协程,kotlin协程
Go言语中的协程(Goroutine)是一种轻量级的线程。它们被规划为在同一地址空间中并发运转,而无需运用操作系统等级的...

-
delphi7序列号,Delphi7序列号获取与运用指南
1.序列号获取办法:能够经过一些东西如keygen.exe或EPSDelphi.v7.exe来生成所需的序列号...
-
宏基蜂鸟swift3,宏基蜂鸟Swift3——轻浮便携,功能杰出的作业利器
宏碁蜂鸟Swift3是一款备受重视的轻浮笔记本电脑,以下是其主要特色和装备信息:外观规划宏碁蜂鸟Swift3采用了...

-
python是免费的吗,Python是免费的吗?全面解析Python的免费特性
Python是免费的,并且是开源的。它由PythonSoftwareFoundation保护,遵从PSF答...

-
python中input, 什么是input()函数?
在Python中,`input`函数用于从用户那里获取输入。它答应用户在程序运行时输入数据,并将其作为字符串回来。这里...

-
r言语建模,R言语在建模中的运用与优势
1.装置R言语和必要的包:下载并装置R言语。装置必要的R包,例如`ggplot2`用于数据可视化,`c...