
机器学习模型构建,机器学习模型构建全解析
 admin
admin机器学习模型构建是一个杂乱的进程,它涉及到多个进程和考虑要素。下面我将为您概述构建机器学习模型的一般进程和考虑要素。
1. 问题界说: 确认您想要处理的问题类型(例如,分类、回归、聚类等)。 清晰模型的预期输出和输入特征。
2. 数据搜集: 搜集与问题相关的数据。 保证数据的质量和多样性,以防止误差。
3. 数据预处理: 清洗数据,处理缺失值、异常值和重复值。 特征工程,绵亘特征挑选、特征提取和特征转化。
4. 模型挑选: 依据问题的性质和数据的特性挑选适宜的算法(例如,线性回归、决议计划树、神经网络等)。 考虑模型的杂乱性和可解说性。
5. 模型练习: 运用练习数据来练习模型。 调整模型参数以优化功能。
6. 模型评价: 运用验证集或测验集来评价模型的功能。 运用恰当的评价目标(例如,准确率、召回率、F1分数等)。
7. 模型调优: 依据评价成果调整模型参数或挑选不同的算法。 运用穿插验证等技能来防止过拟合。
8. 模型布置: 将练习好的模型布置到出产环境中。 保证模型的实时性和可扩展性。
9. 模型监控和保护: 监控模型的功能和稳定性。 定时更新模型以习惯数据的改变。
10. 道德和法令考虑: 保证模型恪守相关法令法规。 考虑模型的公平性、透明性和可解说性。
11. 文档和陈述: 记载模型构建的整个进程。 预备陈述以向利益相关者展现模型的作用和局限性。
12. 继续学习和改善: 盯梢最新的机器学习技能和算法。 依据反应和新的数据不断改善模型。
构建机器学习模型是一个迭代的进程,或许需求屡次测验和调整。重要的是要坚持耐性和敞开的心态,不断学习和习惯新的应战。
浅显易懂:机器学习模型构建全解析
跟着大数据和人工智能技能的飞速发展,机器学习已经成为各行各业处理杂乱问题的利器。本文将浅显易懂地解析机器学习模型的构建进程,协助读者了解这一范畴的中心概念和关键技能。
一、机器学习概述

机器学习是一种使计算机体系能够从数据中学习并做出决议计划或猜测的技能。它经过算法剖析数据,从中提取特征,并树立数学模型,然后完成对不知道数据的猜测。
二、机器学习模型类型
依据学习办法和运用场景,机器学习模型首要分为以下几类:
监督学习:经过已符号的练习数据学习,如分类和回归问题。
无监督学习:经过未符号的数据学习,如聚类和降维问题。
半监督学习:结合符号和未符号数据学习。
强化学习:经过与环境交互学习,如游戏和机器人操控。
三、模型构建进程

机器学习模型的构建一般绵亘以下进程:
数据搜集:搜集与问题相关的数据,如文本、图画、声响等。
数据预处理:对搜集到的数据进行清洗、转化和标准化,以进步模型功能。
特征工程:从原始数据中提取有用的特征,以协助模型更好地学习。
模型挑选:依据问题类型和需求挑选适宜的模型。
模型练习:运用练习数据对模型进行练习,调整模型参数。
模型评价:运用测验数据评价模型功能,如准确率、召回率等。
模型优化:依据评价成果调整模型参数,以进步模型功能。
四、常见机器学习算法
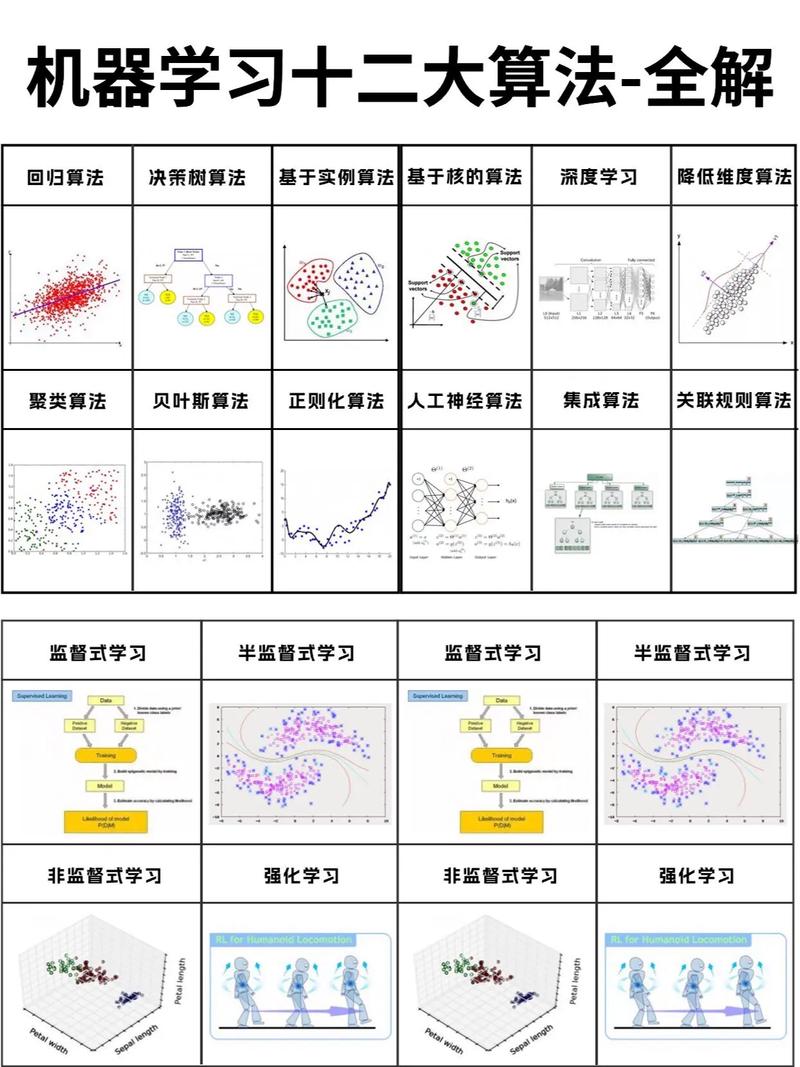
线性回归:用于猜测接连值,如房价猜测。
逻辑回归:用于猜测离散值,如分类问题。
支撑向量机(SVM):用于分类和回归问题。
决议计划树:用于分类和回归问题,易于了解和解说。
随机森林:经过集成多个决议计划树进步模型功能。
神经网络:用于杂乱问题,如图画识别和自然语言处理。
五、模型评价与优化
准确率:猜测正确的样本数占总样本数的份额。
召回率:猜测正确的正样本数占一切正样本数的份额。
F1分数:准确率和召回率的谐和平均数。
穿插验证:将数据集分为多个子集,用于练习和测验模型。
网格查找:经过遍历参数空间,寻觅最优参数组合。
机器学习模型构建是一个杂乱而风趣的进程。经过了解模型构建的进程、常见算法和评价办法,咱们能够更好地应对实际问题,并进步模型功能。期望本文能协助读者更好地了解机器学习模型构建的全进程。
相关文章
-
ai我国,兴起之路与未来展望
1.工业规划与技能立异到2023年6月,我国人工智能中心工业规划现已到达5000亿元,人工智能企业数量超越4400家...

-
ai归纳点评比赛,激起立异潜能,推进人工智能开展
1.归纳性大渠道AIChallenger:由立异工场、搜狗、美团点评、美图联合主办,包含多个不同范畴的比赛,招引...
-
ai归纳事例,归纳事例解析
1.谷歌321个世界级企业AI使用实战事例:谷歌初次公开了321家全球尖端企业的AI使用实战事例,涵盖了零售、...

-
机器学习准确率,界说、重要性及影响要素
机器学习中的准确率(Accuracy)是衡量模型猜测成果正确性的一个重要目标。它表明模型在一切猜测中,正确猜测的份额。准...

-
ai绘画绝色佳人,科技与艺术的完美交融
1.视频资源:哔哩哔哩上有一些关于AI绘画绝色佳人的视频,例如:2.文章和评测:...

-
机器学习实战源代码
你能够在以下几个链接中找到《机器学习实战》的源代码和相关资源:1.知乎:2.CSDN:3.Gite...

-
机器学习开发,从入门到实践之路
1.数据搜集:首要需求搜集相关数据。数据的质量和数量关于模型的功能至关重要。数据可以来自各种来历,如数据库、API、文...
-
资料机器学习,改造资料科学的研讨与开发
资料机器学习(MaterialsMachineLearning)是一个快速开展的范畴,它结合了资料科学、物理、化学和...
