
机器学习代码,机器学习代码实战攻略
 admin
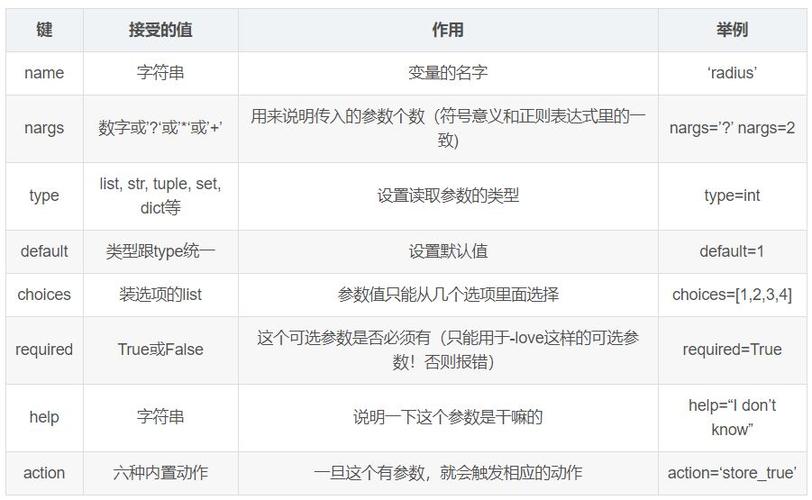
admin1. 线性回归
线性回归是一种用于猜测数值型输出的监督学习算法。以下是一个简略的线性回归示例,运用Python的`scikitlearn`库:
示例数据X = np.array, , , , qwe2qwe2y = np.arrayqwe2
2. 决策树
决策树是一种用于分类和回归的监督学习算法。以下是一个简略的决策树分类示例:
```pythonfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.datasets import load_iris
加载示例数据data = load_irisX = data.datay = data.target
3. 支撑向量机(SVM)
支撑向量机是一种强壮的监督学习算法,常用于分类问题。以下是一个简略的SVM分类示例:
```pythonfrom sklearn.svm import SVCfrom sklearn.datasets import make_classification
生成示例数据X, y = make_classification
4. 神经网络
神经网络是一种模仿人脑作业原理的算法,常用于复杂问题的建模。以下是一个简略的神经网络分类示例:
```pythonfrom sklearn.neural_network import MLPClassifier
生成示例数据X, y = make_classification
这些示例仅仅机器学习领域中的冰山一角。依据你的详细需求,你能够挑选不同的算法和东西来完结你的方针。假如你有更详细的问题或需求,请随时告诉我。
浅显易懂:机器学习代码实战攻略

一、环境建立
在进行机器学习代码编写之前,首要需求建立一个适宜的环境。以下是一个根本的Python机器学习环境建立过程:
装置Python:从Python官网下载并装置Python,引荐运用Python 3.6及以上版别。
装置Anaconda:Anaconda是一个Python发行版,包含了很多科学核算库,如NumPy、Pandas、Scikit-learn等。
创立虚拟环境:运用Anaconda创立一个虚拟环境,以便办理项目依靠。
装置依靠库:在虚拟环境中装置必要的机器学习库,如Scikit-learn、TensorFlow、PyTorch等。
二、数据预处理
数据预处理是机器学习流程中的关键过程,它包含数据清洗、数据转化、特征提取等。以下是一个简略的数据预处理示例:
import pandas as pd
加载数据
data = pd.read_csv('data.csv')
数据清洗
data = data.dropna() 删去缺失值
data = data[data['column'] > 0] 过滤掉不符合条件的行
数据转化
data['column'] = data['column'].astype(float) 将数据类型转化为浮点数
特征提取
X = data[['feature1', 'feature2']] 特征
区分练习集和测验集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
三、模型挑选与练习
在完结数据预处理后,接下来需求挑选适宜的模型并进行练习。以下是一个运用Scikit-learn库进行线性回归模型练习的示例:
from sklearn.metrics import mean_squared_error
创立线性回归模型
练习模型
猜测测验集
评价模型
mse = mean_squared_error(y_test, y_pred)
print('均方差错:', mse)
四、模型评价与优化
在模型练习完结后,需求对模型进行评价和优化。以下是一个运用Scikit-learn库进行模型评价和优化的示例:
穿插验证
打印穿插验证成果
print('穿插验证评分:', scores)
模型优化
设置参数网格
param_grid = {'alpha': [0.001, 0.01, 0.1, 1]}
创立网格查找目标
履行网格查找
grid_search.fit(X_train, y_train)
获取最佳参数
best_params = grid_search.best_params_
print('最佳参数:', best_params)
本文经过实战事例,介绍了机器学习代码编写的根本流程,包含环境建立、数据预处理、模型挑选与练习、模型评价与优化等。期望本文能帮助您更好地了解机器学习代码编写,为您的机器学习之路奠定根底。
相关文章
-
机器学习验证码, 机器学习验证码的原理
机器学习验证码是一种运用机器学习技能来生成和辨认的验证码。传统的验证码是经过随机生成一系列字符或图画来避免主动化东西进行...

-
ai归纳实践报,探究立异,赋能未来
1.言笔AI智能写作软件:言笔AI的实践陈述生成器能够协助用户生成契合标准、内容丰富的陈述。用户只需供给要害信...

-
猜测模型机器学习,未来数据剖析的要害技能
猜测模型是机器学习中的一个重要运用,它运用历史数据来猜测未来事情或趋势。以下是猜测模型的一些要害步骤和类型:1.数据搜...

-
ai归纳智能使用,推进工业革新与立异
1.智能客服:经过自然语言处理和机器学习技能,AI可以了解用户的问题并供给相应的答复,进步客户服务的功率和满意度。2....

-
多模态ai,交融多感官体会,敞开智能新时代
多模态AI是指能够了解和处理多种不同类型数据(如文本、图画、音频和视频)的人工智能体系。这种体系能够归纳多种感官信息,然...

-
ai的使用,重塑未来,赋能各行各业
1.主动驾驶:AI技能被用于主动驾驶轿车,以进步路途安全性和交通功率。2.医疗健康:AI在医疗范畴的使用包含疾病确诊...

-
归纳布线ai绘图,AI绘图在归纳布线规划中的运用与展望
1.boardmixboardmix是一款集成了AI技能的绘图东西,特别适宜规划师和架构师运用。它供给了快捷...

-
Ai综合排名,揭秘全球抢先的人工智能技能
1.全球AI产品排名:2024年全球百大AI产品排名由闻名危险投资公司a16z发布,ChatGPT凭仗其杰出功...
