
散布式联系型数据库,技能解析与商场展望
 admin
admin散布式联系型数据库是一种将数据散布在多个物理方位上的数据库体系。它经过将数据涣散存储在多个节点上,完成了数据的高可用性、可扩展性和容错性。散布式联系型数据库一般选用散布式业务处理和散布式查询优化技能,以确保数据的一致性和查询功率。
散布式联系型数据库的主要特色包含:
1. 高可用性:经过将数据散布在多个节点上,即便某个节点产生毛病,其他节点依然能够持续供给服务,然后确保了体系的高可用性。
2. 可扩展性:散布式联系型数据库能够便利地添加或削减节点数量,以习惯不断改变的数据量和用户需求。这种可扩展性使得体系能够跟着业务的开展而不断扩展。
3. 容错性:散布式联系型数据库经过数据备份和毛病搬运机制,能够在节点毛病时主动康复数据,确保数据的完整性和一致性。
4. 散布式业务处理:散布式联系型数据库支撑散布式业务处理,即一起在一个或多个节点上履行多个操作,并确保这些操作要么悉数成功,要么悉数失利,然后确保了数据的一致性。
5. 散布式查询优化:散布式联系型数据库经过散布式查询优化技能,将查询使命分解为多个子使命,并在多个节点上并行履行,然后进步了查询功率。
常见的散布式联系型数据库包含MySQL Cluster、Oracle RAC、SQL Server AlwaysOn等。这些数据库体系在散布式架构、业务处理和查询优化方面都有共同的完成方法,以满意不同使用场景的需求。
散布式联系型数据库:技能解析与商场展望
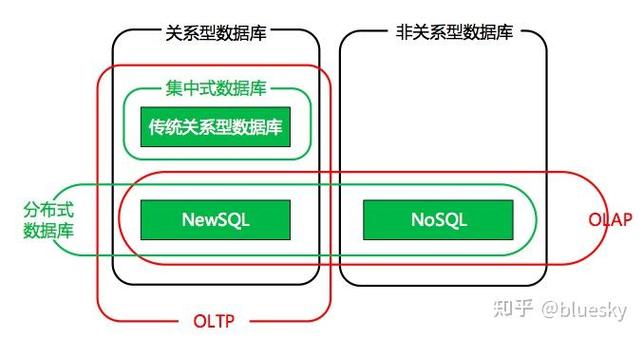
一、散布式联系型数据库的界说与特色
散布式联系型数据库是指在多个物理节点上散布存储数据,经过散布式架构完成数据的高效拜访和处理的数据库体系。其主要特色如下:
横向扩展:经过添加节点来进步体系处理才能和存储容量。
高可用性:经过数据冗余和毛病搬运机制,确保体系在呈现毛病时仍能正常运转。
高功用:经过散布式架构和优化算法,完成数据的高效拜访和处理。
兼容性:支撑规范的SQL语法,便利用户搬迁现有使用。
二、散布式联系型数据库的技能架构
散布式联系型数据库一般选用以下技能架构:
数据分片:将数据依照必定的规矩涣散存储到多个节点上。
散布式业务:经过散布式业务管理器,确保业务的原子性、一致性、阻隔性和持久性。
数据仿制:经过数据仿制机制,完成数据的冗余备份和毛病搬运。
负载均衡:经过负载均衡机制,完成恳求的均匀分配,进步体系功用。
三、散布式联系型数据库的使用场景
散布式联系型数据库适用于以下场景:
高并发场景:如电商渠道、在线付出等,需求处理很多并发恳求。
大数据场景:如搜索引擎、数据剖析等,需求处理海量数据。
高可用场景:如金融、电信等,需求确保体系的高可用性。
四、散布式联系型数据库的商场展望
跟着大数据、云核算等技能的不断开展,散布式联系型数据库商场呈现出以下趋势:
开源与商业并存:开源散布式联系型数据库如TiDB、CockroachDB等,在商场上逐步锋芒毕露;一起,商业散布式联系型数据库如OceanBase、GaussDB等,也凭仗其高功用、高可用性等特色,遭到企业喜爱。
云原生化:跟着云核算的遍及,散布式联系型数据库将愈加重视云原生特性,如弹性弹性、主动化运维等。
功用多样化:散布式联系型数据库将不断丰富功用,如支撑实时剖析、机器学习等,满意更多使用场景的需求。
散布式联系型数据库凭仗其高功用、高可用性等特色,成为现代企业数据管理的重要东西。跟着技能的不断开展,散布式联系型数据库商场将呈现出愈加昌盛的现象,为企业供给愈加优质的数据服务。
相关文章
-
怎样衔接数据库,全面攻略
衔接数据库一般需求以下几个进程:1.确认数据库类型:首先要清晰你要衔接的数据库类型,如MySQL、PostgreSQL...

-
大数据与数据库的联系,大数据与数据库的界说
大数据与数据库是两个密切相关但又不完全相同的概念。首要,数据库是用于存储、办理和检索数据的体系。它一般用于存储结构化数据...
-
联系型数据库与非联系型数据库的差异
联系型数据库(RDBMS)和非联系型数据库(NoSQL)是两种不同的数据存储解决方案,它们在数据模型、查询言语、扩展性、...

-
同路大数据
同路科技是一家专心于大数据智能办理的创新式科技企业。公司使用大数据、云核算及人工智能技术,致力于发掘海量数据背面的价值,...
-
数据库书本引荐,精选书本引荐攻略
1.《数据库体系概念》(DatabaseSystemConcepts)作者:AbrahamSilbersch...

-
怎么规划数据库,从需求剖析到施行保护的全面攻略
规划数据库是一个体系化的进程,需求考虑数据的存储、检索、保护和安全性。以下是规划数据库的根本进程:1.需求剖析:...

-
mysql 新增一列,mysql 怎样给表新增一列id
在MySQL中,你能够运用`ALTERTABLE`句子来为现有表新增一列。以下是根本的语法:```sqlALTER...

-
access数据库程序规划是什么,什么是Access数据库程序规划?
1.数据库创立:首要,您需求创立一个新的Access数据库文件,这通常是一个.accdb文件。在创立进程中,您可认为数...
