
大数据搜集办法有,大数据搜集办法概述
 admin
admin1. 网络爬虫:经过编写程序主动抓取网络上的揭露信息,如网页、交际媒体、论坛等。网络爬虫需求恪守相关法律法规和网站的运用协议,防止侵略隐私和知识产权。
2. API接口:许多网站和运用程序供给API接口,答应开发者以编程办法获取数据。经过API接口能够获取结构化数据,如天气预报、股票价格、新闻资讯等。
3. 日志文件:服务器和运用程序发生的日志文件是重要的数据来历。日志文件记载了用户行为、体系过错、拜访记载等信息,能够用于剖析用户行为、优化体系功能等。
4. 传感器数据:物联网设备、智能设备等发生的传感器数据是大数据的重要来历。传感器数据能够用于监控环境、猜测设备毛病、优化生产流程等。
5. 问卷调查:经过问卷调查能够搜集用户定见、需求、行为等信息。问卷调查需求规划合理的问卷,并保证样本的代表性。
6. 交际媒体数据:交际媒体渠道如微博、微信、抖音等发生了很多用户生成内容。经过剖析交际媒体数据,能够了解用户爱好、定见、行为等信息。
7. 第三方数据:许多公司供给商业数据服务,如人口统计数据、消费数据、职业陈述等。第三方数据能够用于市场剖析、竞赛剖析等。
8. 揭露数据:政府、研讨机构等揭露的数据也是重要的数据来历。揭露数据能够用于社会研讨、方针剖析等。
9. 数据发掘:从已有数据中发掘有价值的信息。数据发掘技能包含分类、聚类、相关规矩发掘等。
10. 数据清洗和预处理:搜集到的数据往往存在过错、缺失、重复等问题,需求进行清洗和预处理,以保证数据的质量。
11. 数据交融:将来自不同来历的数据进行交融,以取得更全面、更精确的信息。
12. 数据隐私维护:在搜集和运用数据时,需求恪守相关法律法规,维护用户隐私。
大数据搜集办法的挑选取决于具体的运用场景和数据需求。在实践运用中,或许需求结合多种搜集办法,以获取更全面、更精确的数据。
大数据搜集办法概述
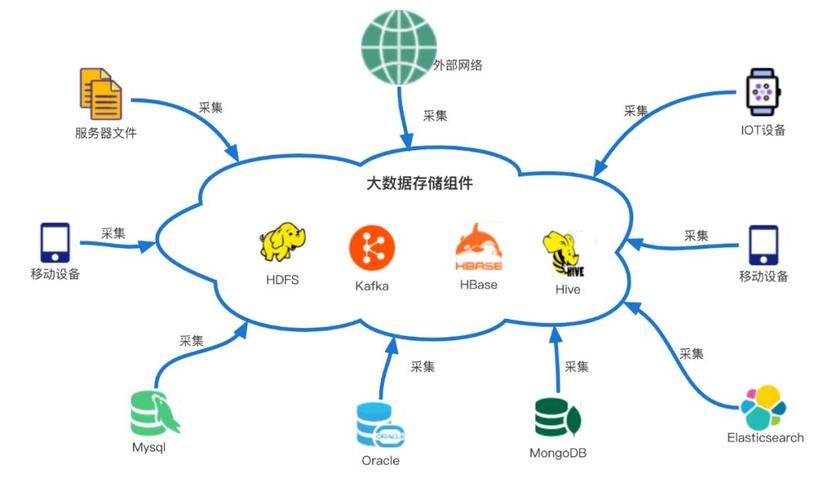
跟着信息技能的飞速发展,大数据已经成为各行各业的重要资源。大数据搜集作为大数据处理流程的第一步,其重要性显而易见。本文将具体介绍大数据搜集的办法,协助读者更好地了解和运用这一技能。
数据搜集的基本概念
数据搜集是指从各种来历获取、转化和传输很多数据的进程。这些来历包含数据库、交际媒体、物联网设备等。数据搜集的意图是为了将这些数据转化为有价值的信息,以支撑决议方案拟定和数据剖析。
数据搜集的办法分类
依据数据搜集的办法和东西,能够将数据搜集办法分为以下几类:
1. 体系日志搜集
体系日志搜集是互联网企业常用的数据搜集办法。经过Hadoop的Chukwa、Cloudera的Flume和Facebook的Scribe等东西,能够完成对海量日志数据的搜集和传输。这些东西选用分布式架构,能够满意每秒数百MB的日志数据搜集和传输需求。
2. 网络数据搜集
网络数据搜集首要经过网络爬虫或网站揭露API等办法从网站上获取数据信息。这种办法能够将非结构化数据从网页中抽取出来,存储为一致的本地数据文件,并以结构化的办法存储。
3. 其他数据搜集办法
关于企业生产经营数据或学科研讨数据等保密性要求较高的数据,能够经过与企业或研讨机构协作,运用特定体系接口等相关办法搜集数据。
数据搜集的进程
数据搜集是一个杂乱的进程,需求遵从以下进程:
1. 确认需求
清晰需求搜集的数据类型和方针,为后续的数据搜集作业供给方向。
2. 确认搜集办法
依据需求挑选适宜的数据搜集办法和技能,保证数据搜集的精确性和可靠性。
3. 拟定搜集方案
确认搜集的时刻、频率和规模,拟定具体的搜集方案,保证数据搜集的有序进行。
4. 搜集数据
依照搜集方案进行数据搜集,保证数据的完整性和精确性。
5. 数据清洗和处理
对搜集到的数据进行清洗、去重、格局转化等处理,以保证数据的精确性和可靠性。
6. 数据存储
将处理后的数据存储在恰当的存储介质中,以便后续的剖析和处理。
数据搜集的东西

1. Flume
Flume是Hadoop的组件,由Cloudera专门研制的分布式日志搜集体系。它供给了从Console、RPC、Text、Tail、Syslog、Exec等数据源上搜集数据的才能,适用于大部分的日常数据搜集场景。
2. Scrapy
Scrapy是一个开源的网络爬虫结构,能够用来构建爬虫程序,从网站中提取数据。
3. Logstash
Logstash是一个开源的数据搜集和传输东西,能够将数据从各种来历(如日志文件、数据库等)搜集起来,并进行过滤、转化和传输。
大数据搜集是大数据处理流程的第一步,关于数据剖析和决议方案拟定具有重要意义。本文介绍了大数据搜集的基本概念、办法、进程和东西,期望对读者有所协助。
相关文章
-
mysql设置主键自增,高效数据办理的要害
在MySQL中,设置一个字段为主键并使其自增是一个常见的操作。下面是如安在创立表时以及修正已存在的表时设置主键自增的过程...

-
linux检查mysql,Linux体系中检查MySQL的具体办法攻略
检查MySQL服务状况1.运用`systemctl`指令(假如体系运用的是Systemd作为初始化体系):``...

-
mysql5.0,回忆与展望
MySQL5.0是MySQL数据库办理体系的一个版别,开始发布于2005年。它是MySQL数据库的一个里...

-
贵州省大数据,大数据引领下的立异与开展
开展概略1.安排架构:2017年2月,贵州省公共服务办理办公室更名为贵州省大数据开展办理局,成为省人民政府正厅级直属...

-
检查数据库进程,怎么检查数据库进程
1.MySQL:运用指令行东西`mysql`登录数据库后,履行`SHOWPROCESSLIST;`指...

-
oracle切割字符串, Oracle字符串切割的常用函数
Oracle字符串切割:高效处理字符串数据的技巧在Oracle数据库中,字符串处理是日常操作中不可或缺的一部分。字符串...

-
oracle视图,功用、运用与优势
Oracle视图是一个虚拟表,它包括了一个或多个表中的数据。视图能够简化杂乱的查询,供给安全的数据拜访操控,以及创立数...

-
开源免费的向量数据库是什么,什么是开源免费的向量数据库?
1.Faiss:由FacebookAIResearch开发,是一个高效类似性查找和密布向量聚类的库。它支撑多种间隔...
