
mysql是散布式数据库吗,什么是散布式数据库?
 admin
adminMySQL自身是一个联系型数据库办理体系,它不是散布式数据库。MySQL一般运转在单个服务器上,尽管它能够经过仿制、集群和连接器等方法完成散布式存储和拜访。
MySQL能够与一些散布式数据库体系(如MySQL Cluster、Galera Cluster等)结合运用,以完成散布式数据库的功用。这些体系能够在多个服务器上分配数据和负载,进步功用、可靠性和可扩展性。
总归,MySQL自身不是散布式数据库,但能够与其他散布式数据库体系结合运用,以完成散布式数据库的功用。
什么是散布式数据库?
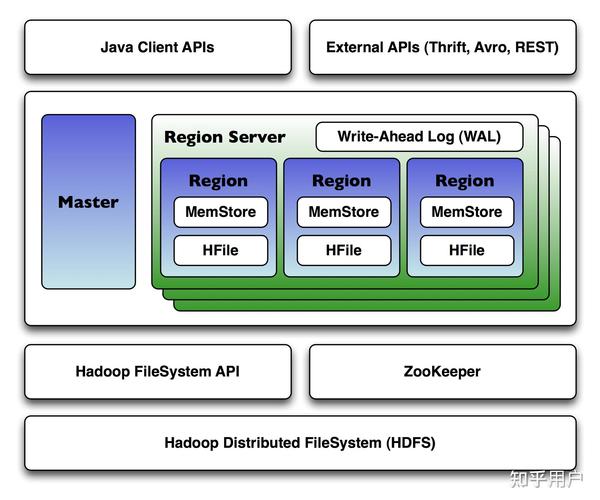
散布式数据库是指将数据散布存储在多个物理方位上,经过网络连接起来,构成一个逻辑上一致的数据库体系。这种架构能够有效地进步数据的可用性、扩展性和功用,满意大规模数据存储和高并发拜访的需求。
MySQL:联系型数据库的佼佼者

MySQL是一款广泛运用的联系型数据库办理体系(RDBMS),以其高功用、可靠性、易用性等特色遭到很多开发者和企业的喜爱。传统的MySQL数据库在处理大规模数据和高并发拜访时,可能会遇到功用瓶颈。
MySQL能否成为散布式数据库?
尽管MySQL自身并不原生支撑散布式数据库,但经过一些技能手段,能够完成散布式布置和数据分片,然后满意散布式数据库的需求。
MySQL完成散布式数据库的技能手段
以下是几种常见的MySQL完成散布式数据库的技能手段:
1. 数据库分片(Sharding)
数据库分片是将数据库水平切分红多个分片,每个分片存储不同的数据集。经过分片键来确认数据应该存储在哪个分片中,然后完成数据的散布式存储。常见的分片战略有依据规模、哈希和列表等。
2. 数据仿制(Replication)
MySQL支撑主从仿制,能够将数据从主库仿制到多个从库中。读写别离能够将读操作分发到不同的从库上,进步读取功用;高可用功用够确保当主库产生毛病时,从库能够接收服务。
3. 散布式业务
MySQL原生不支撑跨节点的散布式业务,但能够经过应用层的方法来完成散布式业务,例如运用散布式业务结构(如Seata、TCC-Transaction等)或许自行设计完成。
MySQL散布式数据库的优势
运用MySQL完成散布式数据库具有以下优势:
1. 高可用性和容错性
经过数据副本和主动毛病搬运机制,确保数据的高可用性。当一个节点产生毛病时,其他节点能够主动接收其作业负载,确保体系的接连运转。
2. 高功用和可扩展性
经过水平扩展技能(如分片、仿制等)进步功用和可扩展性。用户能够依据需求自由地添加或削减节点,以满意不断增加的数据处理需求。
3. 灵敏的布置方法
MySQL散布式数据库支撑多种布置方法,如主从仿制、集群形式等。用户能够依据自己的需求挑选最适合的布置方法。
4. 老练的生态体系
MySQL散布式数据库具有丰厚的东西和插件生态体系,包含备份康复东西、监控告警东西、功用优化东西等。这些东西能够协助用户更轻松地办理和保护散布式数据库。
尽管MySQL自身并不原生支撑散布式数据库,但经过一些技能手段,能够完成散布式布置和数据分片,满意散布式数据库的需求。运用MySQL完成散布式数据库具有高可用性、高功用、可扩展性等优势,是很多企业和开发者的挑选。
相关文章
-
数据库的数据类型有哪些, 整数类型
1.整数类型:`INT`:用于存储整数。`SMALLINT`:用于存储较小的整数。`TINYI...

-
暗黑2数据库,全面解析游戏配备与技术
以下是几个关于《暗黑破坏神2》数据库的引荐网站,你能够依据自己的需求进行挑选:1.暗黑2数据库暗黑2重制版数据库...

-
linux发动oracle,二、准备工作
在Linux体系中发动Oracle数据库,一般需求履行一系列指令。这些指令依赖于您的Oracle版别和具体的体系装备。下...

-
金融大数据剖析,驱动金融职业革新的新引擎
金融大数据剖析是指运用大数据技能对金融范畴的数据进行搜集、存储、处理和剖析,以提取有价值的信息和常识,为金融决议计划供给...

-
大数据开展的趋势,未来机会与应战并存
大数据开展的趋势能够从以下几个方面来讨论:1.数据量的持续添加:跟着物联网、云核算、人工智能等技能的快速开展,数据的发...

-
华师大数据库,深化了解华师大公共数据库——学术研讨的得力助手
华东师范大学供给了多种数据库和电子资源供师生运用。以下是首要的数据库资源及其运用说明:1.华东师范大学公共数据库:...

-
sqlite3数据库,SQLite3数据库简介
SQLite是一个轻量级的数据库,它是一个C言语库,供给了一个轻量级的磁盘数据库,它不需求独立的数据库服务器进程。SQL...

-
antdb数据库,国产数据库的兴起与未来展望
AntDB数据库是一款国产自主、高功用、可扩展、高牢靠的分布式联系型数据库。以下是关于AntDB数据库的具体介绍:1....
