
查找引擎数据库,查找引擎数据库概述
 admin
admin查找引擎数据库是一类专门用于数据内容查找的NoSQL数据库,首要用于非结构化大数据处理和剖析范畴。以下是关于查找引擎数据库的详细信息:
界说查找引擎数据库是一种专门用于数据内容查找的NoSQL数据库,能够高效地处理和剖析非结构化数据。非结构化数据一般没有预界说的数据模型,无法用传统的数据库二维逻辑来体现,但却蕴含着巨量的价值信息。
特色1. 高效的数据检索:查找引擎数据库供给快速的数据检索服务,是查找引擎体系的底层支撑。2. 支撑多种数据类型:能够存储和索引结构化、非结构化文本、数字数据和地舆空间数据。3. 分布式特性:支撑快速扩展,能够跟着数据和查询量的增加无缝扩展。4. 全文查找和剖析:支撑全文查找,能够发现数据中的趋势和形式。
常见查找引擎数据库1. Elasticsearch: 依据Lucene构建,支撑全文查找,供给丰厚的API。 具有分布式特性,能够处理大规模数据。 支撑杂乱查询和数据剖析。
2. Solr: 也是依据Lucene构建的查找引擎,供给高效的查找和索引功用。 支撑多种数据格式和查询言语。
3. Sphinx: 开源查找引擎,常用于全文查找,支撑多种编程言语和数据库。
应用场n2. 电商渠道:查找产品、处理用户查询、个性化引荐等。3. 日志剖析:搜集和剖析体系日志,监控体系状况。
作业原理查找引擎数据库的作业原理首要包括以下几个进程:1. 数据收集:从互联网上抓取网页数据。2. 树立索引:对数据进行索引,以便快速检索。3. 查找和查询:依据用户输入的查询条件,在索引中检索相关数据。4. 成果排序:依据相关性对查找成果进行排序。
查找引擎数据库概述
查找引擎数据库是查找引擎的中心组成部分,它担任存储、办理和检索互联网上的海量信息。查找引擎数据库经过索引技能,将网页内容转化为可检索的数据结构,使得用户能够快速找到所需的信息。
查找引擎数据库的结构
查找引擎数据库一般由以下几个部分组成:
索引:索引是查找引擎数据库的中心,它包括了网页的URL、标题、描绘、关键词等信息,以便于快速检索。
缓存:缓存是查找引擎数据库中存储网页内容的部分,它答应查找引擎在用户恳求时直接从缓存中获取网页内容,进步检索速度。
倒排索引:倒排索引是一种数据结构,它将关键词映射到包括该关键词的网页列表,使得查找进程愈加高效。
数据库:数据库用于存储索引、缓存和倒排索引等数据,保证查找引擎数据库的稳定性和可扩展性。
查找引擎数据库的索引技能
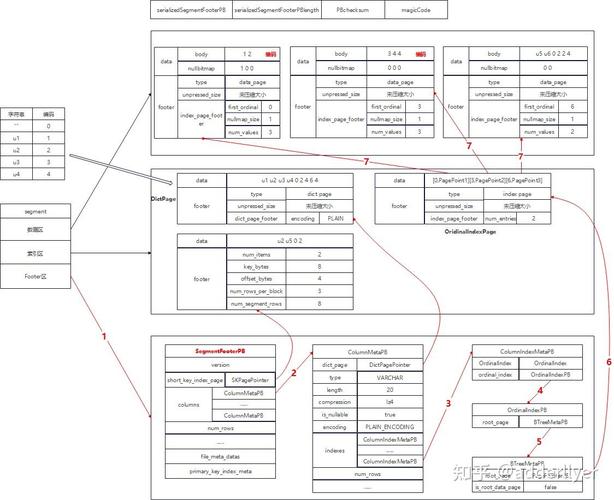
全文索引:全文索引能够对网页内容进行全文检索,用户能够经过关键词查找到包括该关键词的网页。
倒排索引:倒排索引将关键词映射到包括该关键词的网页列表,使得查找进程愈加高效。
布尔索引:布尔索引答应用户运用布尔运算符(如AND、OR、NOT)进行杂乱的查找。
地舆位置索引:地舆位置索引能够将网页与地舆位置信息相关,便于用户查找特定区域的网页。
查找引擎数据库的缓存机制
页面缓存:页面缓存将网页内容存储在内存中,当用户再次拜访同一网页时,能够直接从缓存中获取内容,削减服务器负载。
目标缓存:目标缓存将数据库查询成果存储在内存中,削减数据库拜访次数,进步查询功率。
CDN缓存:CDN(内容分发网络)缓存能够将网页内容分发到全球各地的服务器,削减用户拜访推迟。
查找引擎数据库的更新和保护
网页抓取:定时抓取互联网上的新网页,更新索引和缓存。
网页更新检测:检测网页内容的更新,及时更新索引和缓存。
索引优化:定时对索引进行优化,进步检索功率。
数据库保护:定时对数据库进行备份和整理,保证数据库的稳定性和安全性。
查找引擎数据库的功能优化
硬件晋级:进步服务器硬件功能,如CPU、内存、硬盘等。
数据库优化:优化数据库装备,如索引优化、查询优化等。
缓存战略优化:优化缓存战略,进步缓存命中率。
负载均衡:运用负载均衡技能,涣散拜访压力,进步体系可用性。
查找引擎数据库是查找引擎的中心组成部分,它经过索引、缓存、倒排索引等技能,完成了对海量信息的快速检索。了解查找引擎数据库的结构、技能、更新和保护战略,关于优化查找引擎功能和提高用户体会具有重要意义。
相关文章
-
大数据对科技的影响,科技开展的新引擎
大数据对科技的影响是深远的,它正在改动咱们与国际互动的办法,推进科技立异,并重塑各个工作。以下是大数据对科技影响的一些要...

-
sql别离数据库,什么是SQL别离数据库?
别离数据库一般意味着将一个数据库从其当时的环境中移除,以便将其移动到另一个方位或环境。这一般涉及到将数据库的数据文件和业...

-
linux装置oracle数据库,Linux环境下装置Oracle数据库的具体攻略
在Linux上装置Oracle数据库是一个多进程的进程,需求保证你的体系满意Oracle的最低要求,并装置必要的依靠项。...

-
大数据操作体系,大数据操作体系概述
大数据操作体系是一个专门为处理和剖析大规模数据集而规划的软件体系。它一般包含以下几个要害组件:1.数据存储:大数据操作...

-
SQL数据库有哪些, 什么是SQL数据库?
1.MySQL:由Oracle公司支撑的开源联系数据库办理体系,广泛使用于Web使用中。2.PostgreSQL:一...

-
db2创立数据库,DB2数据库创立攻略
在DB2中创立数据库的进程一般包含确认数据库的称号、巨细、存储方位等参数。以下是一个根本的进程攻略:1.确认数据库的称...

-
数据库衔接方法,数据库衔接方法概述
数据库衔接方法概述在当今的信息化年代,数据库作为数据存储和办理的中心,其衔接方法的挑选关于体系的稳定性和功用至关重要。数...

-
数据库办理体系是体系软件吗,什么是数据库办理体系(DBMS)
是的,数据库办理体系(DatabaseManagementSystem,简称DBMS)是一种体系软件。它用于办理和安...
