
spark大数据剖析,技能解析与运用实践
 admin
adminSpark 是一个快速、通用、可扩展的大数据处理结构,它供给了一种简略而强壮的编程模型,用于处理大规模数据集。Spark 支撑多种编程言语,包含 Scala、Java、Python 和 R,使得开发人员可以轻松地构建杂乱的数据处理运用程序。
以下是 Spark 大数据剖析的一些要害特色和优势:
1. 速度和功能:Spark 运用内存核算,可以明显进步数据处理速度。与传统的磁盘核算比较,Spark 可以在内存中处理数据,然后加快了数据处理的功率。
2. 易用性:Spark 供给了一个简略的 API,使得开发人员可以轻松地构建数据管道。Spark 的 API 支撑多种编程言语,包含 Scala、Java、Python 和 R,使得开发人员可以挑选他们了解的言语进行开发。
3. 可扩展性:Spark 可以在单个节点上运转,也可以在集群上运转。Spark 支撑多种集群办理器,包含 Hadoop YARN、Apache Mesos 和 Spark 自带的独立调度器。这使得 Spark 可以轻松地扩展到大规模的集群上。
4. 数据源集成:Spark 支撑多种数据源,包含 HDFS、Cassandra、HBase、Hive、Tachyon 和 S3。这使得 Spark 可以轻松地与现有的数据存储体系集成。
5. 丰厚的库和东西:Spark 供给了丰厚的库和东西,用于处理各种类型的数据。例如,Spark MLlib 是一个机器学习库,Spark GraphX 是一个图处理库,Spark SQL 是一个用于处理结构化数据的库。
6. 实时处理:Spark 支撑实时数据处理,可以实时地处理数据流。这使得 Spark 可以用于构建实时数据剖析运用程序,例如实时监控、实时引荐体系等。
7. 容错性:Spark 具有强壮的容错性,可以主动康复失利的使命和节点。这使得 Spark 可以在呈现毛病时坚持数据处理的高可用性。
8. 社区支撑:Spark 具有一个活泼的社区,供给了很多的文档、教程和示例代码。这使得开发人员可以轻松地学习和运用 Spark。
总归,Spark 是一个功能强壮、易于运用的大数据处理结构,可以用于处理各种类型的数据。Spark 的速度、可扩展性、易用性和丰厚的库和东西使其成为大数据剖析的首选结构之一。
Spark大数据剖析:技能解析与运用实践

一、Spark简介
Apache Spark是一个开源的分布式核算体系,旨在处理大规模数据集。它由Scala编写,但一起也供给了Java、Python和R等言语的API。Spark具有以下特色:
高功能:Spark经过内存核算和优化算法,完成了比Hadoop MapReduce快100倍的功能。
通用性:Spark支撑多种数据处理使命,包含批处理、实时处理、机器学习等。
易用性:Spark供给了丰厚的API和东西,便使用户进行编程和开发。
弹性:Spark可以主动处理节点毛病,确保使命的安稳运转。
二、Spark中心组件
Spark的中心组件包含:
Spark Core:供给Spark的基本功能,包含RDD(弹性分布式数据集)、使命调度、内存办理等。
Spark SQL:供给SQL查询接口,支撑结构化和半结构化数据。
Spark Streaming:供给实时数据处理才能,支撑流式数据源。
MLlib:供给机器学习算法和东西,支撑多种机器学习使命。
GraphX:供给图核算才能,支撑图算法和图剖析。
三、Spark大数据剖析技能解析
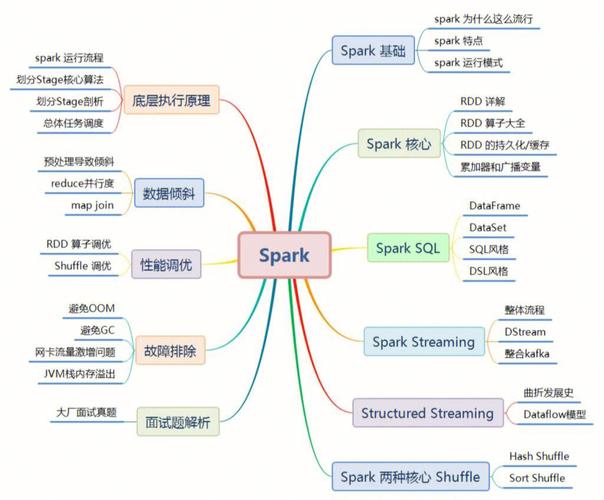
Spark大数据剖析技能首要包含以下方面:
数据收集:经过HDFS、Cassandra、HBase等数据存储体系,将数据收集到Spark集群中。
数据预处理:运用Spark SQL对数据进行清洗、转化和集成,为后续剖析供给高质量的数据。
数据剖析:使用Spark SQL、MLlib等组件进行数据剖析和发掘,包含计算、聚类、分类、猜测等使命。
数据可视化:将剖析成果以图表、报表等方式展现,便使用户了解和决议计划。
四、Spark大数据剖析运用实践
电商引荐体系:使用Spark MLlib进行用户行为剖析,完成个性化引荐。
金融风控:使用Spark进行实时数据剖析,辨认反常买卖,下降金融风险。
交际网络剖析:使用Spark GraphX进行交际网络剖析,发掘用户联系和爱好。
医疗数据剖析:使用Spark进行医疗数据发掘,进步医疗确诊和医治作用。
Apache Spark作为一种高效、通用的大数据处理结构,在各个领域都得到了广泛运用。本文对Spark大数据剖析技能进行了解析,并探讨了其在实践运用中的实践。跟着大数据技能的不断发展,Spark将持续发挥重要作用,为企业和研究机构供给强壮的数据处理和剖析才能。
相关文章
-
云核算大数据人工智能,未来科技开展的三大支柱
云核算、大数据和人工智能是当今信息技能的三大支柱,它们相互促进、相互依存,一起推进着社会的数字化转型和智能化晋级。云核算...

-
数据库试卷,全面查验数据库常识与运用才能
2.《SQLSERVER数据库根底》期终考试试卷及答案:该试卷包含多项选择题,触及数据库根底常识和SQLSe...
-
检查数据库字符集,怎么检查数据库字符集
数据库的字符集是`UTF8`。深化解析:怎么检查数据库字符集在数据库办理中,字符集的设置是一个至关重要的环节。字符集决...
-
mysql搬迁数据库,mysql搬迁数据库到另一台机器
MySQL数据库搬迁一般涉及到将数据从一个MySQL服务器复制到另一个MySQL服务器。这个进程能够包含整个数据库的搬迁...
-
数据库数据模型,数据库数据模型概述
数据库数据模型是描绘数据库中数据结构、数据操作和完整性束缚的一组规矩和约好。它是数据库规划和完成的根底,也是数据库体系办...
-
php创立数据库, 环境预备
在PHP中创立数据库一般涉及到运用SQL句子来操作数据库。以下是一个简略的示例,展现怎么运用PHP和MySQLi扩展来创...
-
数据库维护分为,数据库维护的重要性
数据库维护能够分为多个方面,首要包含以下几个方面:1.数据备份与康复:定时对数据库进行备份,以便在数据丢掉或损坏时能够...
-
oracle批量刺进, 批量刺进数据概述
在Oracle数据库中,批量刺进数据一般是指运用SQL句子将很多数据一次性刺进到表中。这能够经过几种不同的办法完结,包括...