
python读取html文件
 admin
adminPython 读取 HTML 文件:深化解析与数据提取攻略
在当今的互联网年代,HTML 文件作为网页内容的首要载体,其重要性显而易见。Python 作为一种功能强大的编程言语,供给了多种库和东西来读取和解析 HTML 文件。本文将深化探讨耗费运用 Python 读取 HTML 文件,包含基本概念、常用库介绍以及实际操作过程。
一、Python 读取 HTML 文件的基本概念
HTML 文件格局

Python 库介绍
在 Python 中,有几个库能够用来读取和解析 HTML 文件,包含:
- BeautifulSoup:一个从 Python 代码中构建文档树结构的库,用于解析 HTML 和 XML 文档。
- lxml:一个根据 C 的库,供给了高效的 XML 和 HTML 解析器。

- html.parser:Python 规范库中的一个简略 HTML 解析器。
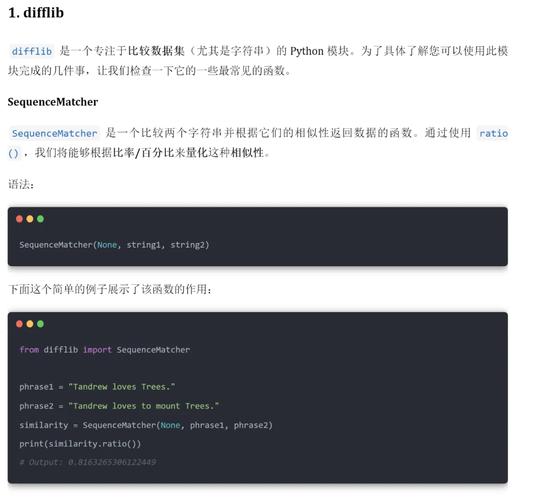
二、装置必要的库

装置 BeautifulSoup

```python
pip install beautifulsoup4
装置 lxml
```python
pip install lxml
三、读取 HTML 文件
运用 BeautifulSoup 读取 HTML 文件
```python
from bs4 import BeautifulSoup
翻开 HTML 文件
with open('example.html', 'r', encoding='utf-8') as file:
html_content = file.read()
解析 HTML 文件
soup = BeautifulSoup(html_content, 'html.parser')
打印解析后的 HTML 文档
print(soup.prettify())
运用 lxml 读取 HTML 文件
```python
from lxml import etree
解析 HTML 文件
tree = etree.parse('example.html')
打印解析后的 HTML 文档
print(etree.tostring(tree, pretty_print=True).decode('utf-8'))
四、解析 HTML 文件
运用 BeautifulSoup 解析 HTML 元素
```python
titles = soup.find_all('h1')
for title in titles:
print(title.get_text())
获取特定 ID 的元素
element = soup.find(id='my-id')
print(element.get_text())
运用 lxml 解析 HTML 元素
```python
titles = tree.xpath('//h1/text()')
for title in titles:
print(title)
获取特定 ID 的元素
element = tree.xpath('//div[@id=\
相关文章
-
css设置字体大小
在CSS中,你能够运用`fontsize`特点来设置字体大小。这个特点能够承受不同的单位,如像素(px)、点(pt)...

-
css子元素挑选器,把握网页款式布局的要害
CSS子元素挑选器用于挑选父元素中的直接子元素。它由两个挑选器组成,第一个挑选器是父元素,第二个挑选器是子元素。它们之间...

-
html躲藏元素
1.运用CSS款式躲藏元素:`display:none;`:将元素彻底从文档流中移除,不占有任何空间。...
-
前端css结构, 什么是CSS结构?
1.Bootstrap:最盛行的前端结构之一,供给了丰厚的组件和呼应式布局。2.Foundation:另一个盛行的前...

-
css3突变特点, 什么是CSS3突变
CSS3突变特点供给了创立滑润过渡颜色的办法,能够使用于布景、边框等元素。突变分为线性突变和径向突变两种。线性突变(L...
-
cn.vue.js, Vue.js简介
Vue.js是一款广泛运用于Web前端开发的JavaScript结构,以其易学易用、功用优胜和灵敏的特色而遭到...

-
react子组件调用父组件办法
在React中,子组件能够经过几种办法调用父组件的办法:1.运用Props传递函数:父组件能够经过props将办法传递...
-
html图片,```html 图片示例
```html图片示例图片示例在这个比如中:请根据您的实践需求调整这些特点。假如您有详细的图片文...