
处理大数据的软件,助力企业高效应对海量数据应战
 admin
admin1. 数据库办理体系: MySQL:一种联系型数据库办理体系,常用于处理结构化数据。 MongoDB:一种NoSQL数据库,适用于存储非结构化数据。 Hadoop:一个开源结构,用于在散布式体系上处理大数据集。 Cassandra:一个散布式NoSQL数据库,适用于高可用性和可扩展性。
2. 数据剖析和可视化东西: Tableau:一个数据可视化东西,用于创立交互式图表和仪表板。 Power BI:微软的数据可视化东西,可以衔接多种数据源并创立陈述。 QlikView:一个数据发现和可视化东西,用于探究和可视化数据。 R言语:一种核算核算和图形展现的言语,常用于数据剖析和可视化。
3. 数据发掘东西: Weka:一个开源的数据发掘东西,包括多种机器学习算法。 Scikitlearn:一个Python库,用于数据发掘和数据剖析。 TensorFlow:一个开源的机器学习结构,适用于深度学习。 Keras:一个高档神经网络API,用于构建和练习模型。
4. 大数据处理借题发挥: Apache Spark:一个开源的大数据处理借题发挥,支撑实时处理和批处理。 Apache Flink:一个流处理结构,用于处理无界和有界数据集。 Apache Storm:一个实时流处理结构,适用于实时大数据处理。
5. 云借题发挥和保管服务: Amazon Web Services :供给各种大数据处理服务,如Amazon Redshift、Amazon EMR等。 Microsoft Azure:供给大数据处理服务,如Azure HDInsight、Azure Databricks等。 Google Cloud Platform :供给大数据处理服务,如Google BigQuery、Google Cloud Dataflow等。
这些软件和东西可以协助你处理、剖析和可视化大数据,然后提取有价值的信息和洞悉。挑选适宜的东西取决于你的详细需求和数据类型。
大数据处理软件:助力企业高效应对海量数据应战

一、Hadoop生态体系
Hadoop生态体系是大数据处理范畴的事实标准,它由多个组件组成,一起完成大数据的存储、处理和剖析。
1. Hadoop散布式文件体系(HDFS)
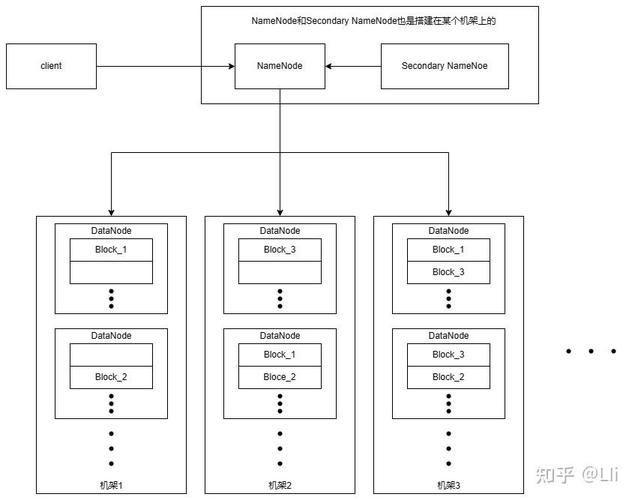
HDFS是Hadoop的中心存储体系,它将文件分割成多个数据块,并将这些数据块存储在集群中的不同节点上。HDFS具有高容错性,可以自动检测和康复数据块的丢掉或损坏。
2. Hadoop散布式核算结构(MapReduce)
MapReduce是Hadoop的中心核算结构,它将大数据分割成多个小的数据块,散布存储在集群中的不同节点上,然后经过散布式核算结构对这些数据进行处理和剖析。
3. YARN

YARN(Yet Another Resource Negotiator)是Hadoop的资源办理器,它担任办理集群中的资源,并将资源分配给不同的应用程序。
4. Hive

Hive是一个数据仓库东西,它可以将结构化数据映射为Hive表,并运用相似SQL的查询言语进行数据查询和剖析。
5. HBase
HBase是一个散布式列式数据库,它适用于存储非结构化和半结构化数据,并支撑实时读取和写入。
二、Spark生态体系
Spark是Hadoop生态体系的有力弥补,它供给了更高效、更灵敏的大数据处理才能。
1. Spark Core
Spark Core是Spark的根底结构,它供给了内存核算、弹性散布式数据集(RDD)等中心功用。
2. Spark SQL
Spark SQL是Spark的数据处理东西,它支撑结构化数据处理,并供给了相似SQL的查询言语。
3. Spark Streaming
Spark Streaming是Spark的实时数据处理东西,它可以实时处理数据流,并支撑多种数据源。
4. MLlib
MLlib是Spark的机器学习库,它供给了多种机器学习算法和东西,便利用户进行数据发掘和剖析。
5. GraphX
GraphX是Spark的图处理库,它供给了图算法和东西,便利用户进行图数据剖析和发掘。
三、其他大数据处理软件
除了Hadoop和Spark,还有一些其他优异的大数据处理软件,以下罗列几款:
1. Kafka

Kafka是一个散布式的流处理借题发挥,它支撑高吞吐量、可扩展性和可靠性的散布式音讯传递。
2. Elasticsearch
Elasticsearch是一个开源的搜索引擎,它可以快速、高效地处理海量数据,并支撑多种数据源。
3. Flink

Flink是一个流处理结构,它支撑实时数据处理,并具有高吞吐量和低推迟的特色。
4. Logstash
Logstash是一个开源的数据搜集和传输东西,它可以从各种数据源中搜集数据,并将其传输到方针体系。
相关文章
-
mysql5,数据库界的经典之作,为何至今仍受喜欢?
MySQL5是一个广泛运用的开源联系型数据库办理体系,它由MySQLAB公司开发,后来被甲骨文公司收买。MyS...

-
企业大数据剖析,敞开智能决议计划新时代
企业大数据剖析是指使用大数据技能对企业内部和外部的海量数据进行搜集、存储、处理、剖析和发掘,以获取有价值的信息和洞悉,然...

-
数据库书面考试,全面解析常见题型及应对战略
数据库书面考试题因为我没有详细的书面考试标题,我将供给一些常见的数据库书面考试题型和考点,协助你预备书面考试。常见题型...

-
数据库redis
Redis是一个开源的运用ANSIC编写的键值对存储数据库。它支撑多种类型的数据结构,如字符串(strings)...

-
oracle表重命名,Oracle数据库中表重命名的操作攻略
在Oracle数据库中,要重命名一个表,能够运用`RENAME`句子。以下是重命名表的语法:```sqlRENAMEo...

-
四川省大数据局
四川省大数据局是四川省政府直属的综合性安排,担任和谐推进全省数据根底准则减少,统筹数据资源整合同享和开发利用,统筹推进“...

-
数据库like,什么是LIKE操作符?
在数据库中,`LIKE`是一个用于在`WHERE`子句中履行形式匹配的运算符。它一般与`%`(表明恣意数量的字符...

-
数据库削减了数据冗余,数据库削减数据冗余的重要性与完成办法
1.规范化和反规范化:经过将数据分解为多个相关表,每个表只包括一组相关数据,能够削减数据冗余。但过度规范化或许会导致查...
