
faiss向量数据库索引,faiss向量数据库
 admin
adminFaiss(Facebook AI Similarity Search)是由Facebook AI Research团队开发的开源库,首要用于快速、高效的向量数据库构建和类似性查找。以下是Faiss中常用的三种索引办法及其特色:
1. IndexFlatL2: 特色:运用欧氏间隔(L2)进行准确检索,适用于较小规划的数据集。 作业原理:选用暴力检索的办法,即核算查询向量与一切数据库向量之间的间隔,然后回来类似度最高的前k个向量。 适用
FAISS向量数据库索引:高效类似性查找的利器
跟着大数据年代的到来,向量数据库在各个范畴得到了广泛运用。FAISS(Facebook AI Similarity Search)作为一款高效的向量数据库索引东西,在类似性查找和向量聚类方面表现出色。本文将具体介绍FAISS的原理、特色以及在实践运用中的优势。
一、FAISS简介
FAISS是由Facebook AI Research开发的一款开源库,首要用于高效类似性查找和密布向量聚类。它支撑多种索引结构,如HNSW(Hierarchical Navigable Small World)、IVF(Inverted Indexed Vector File)和PQ(Product Quantization)等,能够满意不同场景下的需求。
二、FAISS的原理
FAISS的中心思维是将高维向量映射到低维空间,并经过索引结构完成快速检索。以下是FAISS的几个要害原理:
1. 向量索引
FAISS运用多种索引类型来存储向量,以便进行快速的检索。首要包含以下两种:
扁平索引(Flat Index):将一切向量存储在一个大数组中,查找时经过核算查询向量与数据库中每一个向量之间的间隔来找到最近邻。
量化索引(Quantized Index):运用向量量化来削减存储需求和进步查找功率。常用的量化技能包含标量量化(Scalar Quantization, SQ)和乘积量化(Product Quantization, PQ)。
2. 倒排索引(Inverted Index)
关于大规划向量数据库,倒排索引是一种常用的索引结构。它将每个向量映射到一个或多个索引项,然后完成快速检索。
三、FAISS的特色
FAISS具有以下特色:
高效性:FAISS支撑多种索引结构,能够满意不同场景下的需求,完成快速检索。
可扩展性:FAISS支撑分布式存储,能够处理大规划向量数据库。
灵活性:FAISS支撑多种量化技能,能够依据实践需求挑选适宜的量化办法。
开源:FAISS是开源项目,用户能够自在运用和修正。
四、FAISS的运用场景
FAISS在以下场景中具有广泛的运用:
图画检索:经过将图画特征向量存储在FAISS中,能够快速检索与查询图画最类似的图画。
引荐体系:在引荐体系中,FAISS能够用于检索与用户爱好最类似的物品。
自然语言处理:在自然语言处理范畴,FAISS能够用于检索与查询文本最类似的其他文本。
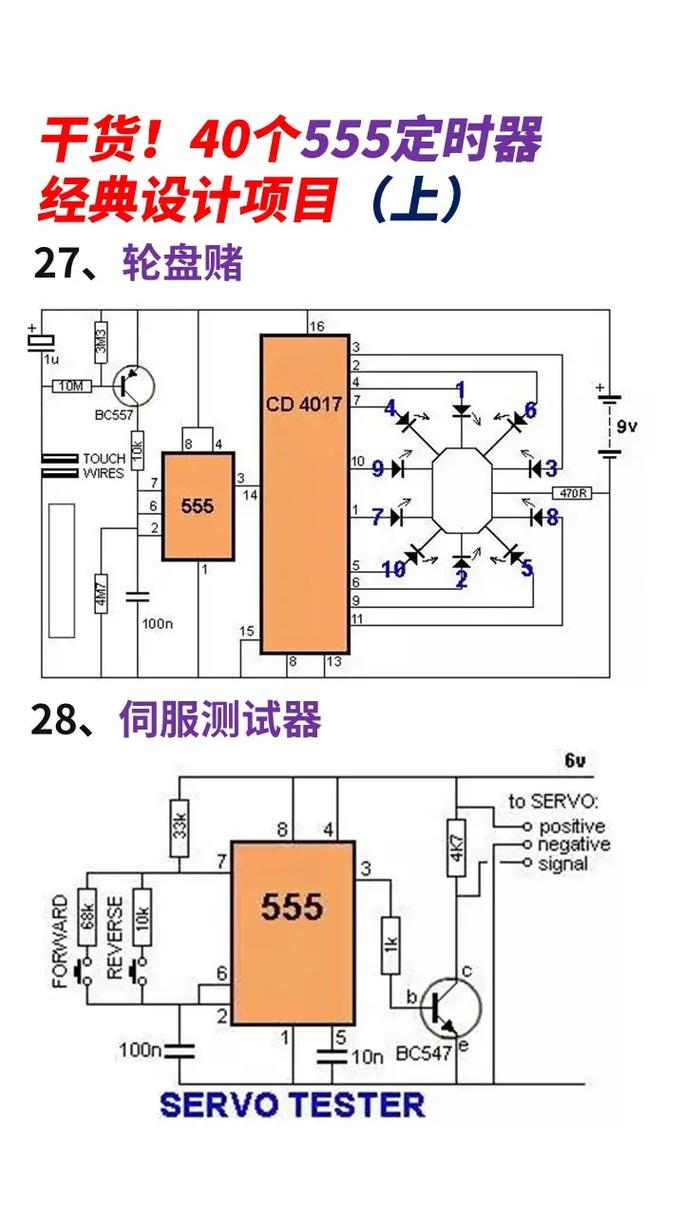
其他范畴:FAISS还能够运用于语音辨认、生物信息学等范畴。
FAISS是一款高效的向量数据库索引东西,在类似性查找和向量聚类方面表现出色。它具有高效性、可扩展性、灵活性和开源等特色,适用于各种场景。跟着大数据年代的到来,FAISS将在更多范畴发挥重要作用。
相关文章
-
数据库1045
MySQL数据库过错1045一般表明“拜访被回绝”,主要原因包含用户名或暗码过错、主机拜访约束、防火墙装备问题以及用户权...

-
华师大公共数据库进口,华东师范大学公共数据库进口详解
华东师范大学公共数据库的进口信息如下:1.一致身份认证渠道:拜访地址:该渠道为华东师范大学师生供给快捷...

-
mysql环境变量,MySQL环境变量装备攻略
MySQL环境变量一般用于装备MySQL客户端和服务器程序的行为。在Windows和Linux体系上,你能够设置环境变量...

-
oracle报价,了解报价构成与购买战略
1.OracleBaseDatabaseServiceOracleBaseDatabaseService...

-
广东省情数据库,广东省情数据库简介
广东省情数据库是一个综合性的信息资源渠道,由广东省人民政府当地志办公室主办,南边新闻网承办。该数据库供给了丰厚的广东省当...

-
大数据外包公司,助力企业智能化转型的得力助手
1.软通动力信息技能(集团)股份有限公司:成立于1995年,软通动力是我国软件与信息技能服务范畴的领军企业之一...

-
揭露数据库,揭露数据库在现代信息社会的重要性与应战
1.CnOpenData数据途径(我国敞开数据):这是一个综合性的敞开数据途径,包括专利、上市公司、新冠疫情等...

-
oracle数据库入门教程, 什么是Oracle数据库?
1.Oracle初级入门教程:链接:内容概述:这份教程专为初学者规划,涵盖了Oracle数据库的根...
