
大数据散布式,大数据散布式概述
 admin
admin大数据散布式体系是指使用散布式核算技能来处理大规模数据集的核算机体系。它将大数据处理使命分解成多个子使命,然后散布到多个核算节点上并行履行,以进步数据处理速度和功率。
散布式体系的规划方针是完成高可用性、可扩展性和容错性。高可用性意味着体系能够在部分节点毛病的情况下持续运转,不会影响整个体系的正常运转。可扩展性是指体系能够依据数据量的添加或削减来动态调整核算资源,以习惯不同的事务需求。容错性是指体系能够在节点毛病或数据丢掉的情况下主动康复,确保数据的完整性和一致性。
大数据散布式体系一般包含以下几个要害组件:
1. 散布式存储:用于存储大规模数据集的存储体系,如Hadoop的HDFS、Google的GFS等。散布式存储体系将数据分红多个块,散布在多个节点上,以完成数据的可靠性和可扩展性。
2. 散布式核算:用于处理大规模数据集的核算结构,如Hadoop的MapReduce、Spark等。散布式核算结构将核算使命分解成多个子使命,然后散布到多个节点上并行履行,以进步核算速度和功率。
3. 数据处理东西:用于处理和剖析大数据的东西,如Hive、Pig、Spark SQL等。这些东西供给了对散布式存储体系中的数据进行查询、剖析和发掘的功用。
4. 资源办理器:用于办理核算资源,如YARN、Mesos等。资源办理器担任分配核算资源给不同的核算使命,并监控使命的履行状况,以确保使命的正常运转。
大数据散布式体系的使用场景十分广泛,包含金融、医疗、教育、电商、交际网络等范畴。经过散布式体系,能够快速处理和剖析大规模数据集,为企业供给有价值的信息和决议计划支撑。
大数据散布式概述
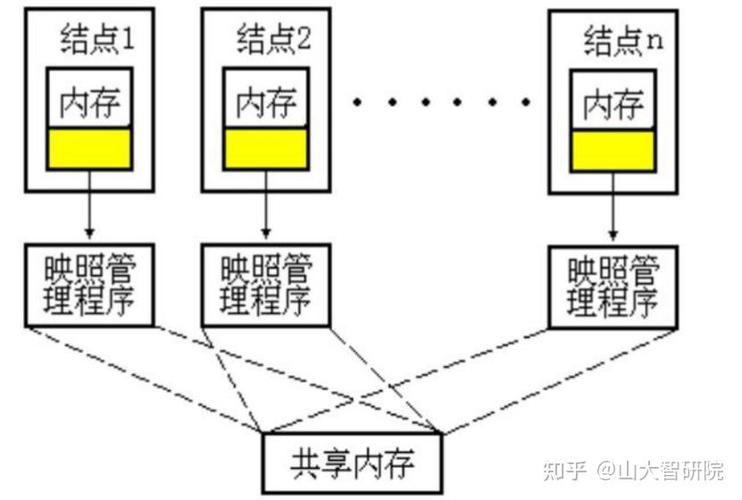
散布式核算的界说与优势
高可用性:散布式体系经过冗余规划,即便部分节点毛病,体系仍能正常运转。
高扩展性:散布式体系能够依据需求动态添加核算节点,进步核算才能。
高功能:散布式核算能够充分使用多台核算机的并行处理才能,进步核算速度。
大数据散布式架构
大数据散布式架构首要包含以下几个中心组件:
数据存储层:如HDFS(Hadoop Distributed File System)、Cassandra、MongoDB等,担任存储海量数据。
数据处理层:如MapReduce、Spark、Flink等,担任对数据进行散布式处理。
数据核算层:如Hive、Pig、Impala等,担任对处理后的数据进行核算和剖析。
数据展现层:如ECharts、Tableau、Power BI等,担任将剖析成果以可视化的方式展现给用户。
Hadoop散布式核算结构
Hadoop是一个开源的散布式核算结构,由Apache基金会开发。它首要处理了大数据存储和处理的问题,具有以下特色:
高容错性:Hadoop将数据切分红多个块,并存储在多个节点上,即便部分节点毛病,数据也不会丢掉。
散布式存储:Hadoop使用多台机器的存储空间,支撑对大规模数据的高效存储和处理。
高吞吐量:Hadoop优化了大规模数据集的读写功能,能够高效处理大容量文件的读写操作。
简化数据一致性模型:Hadoop选用写一次、读屡次的语义模型,简化了数据一致性的办理。
支撑数据本地性:Hadoop优先在存储数据的节点上处理核算使命,然后削减网络传输,进步处理功率。
大数据散布式使用场景
大数据散布式技能在各个范畴都有广泛的使用,以下罗列几个典型使用场景:
搜索引擎:如百度、谷歌等搜索引擎,使用散布式核算技能对海量网页进行索引和排序。
交际网络:如Facebook、Twitter等交际网络,使用散布式核算技能剖析用户行为和爱好。
电子商务:如阿里巴巴、京东等电商渠道,使用散布式核算技能进行产品引荐、广告投进等。
金融职业:如银行、证券等金融机构,使用散布式核算技能进行危险操控、信誉评价等。
医疗健康:如医院、医药企业等,使用散布式核算技能进行疾病猜测、药物研制等。
大数据散布式技能为处理海量数据供给了强壮的支撑,已成为当今年代的重要技能之一。跟着技能的不断发展,大数据散布式将在更多范畴发挥重要作用,推进社会进步。
相关文章
-
oracle创立用户句子,oracle创立用户并指定表空间
在Oracle数据库中,创立用户的句子一般运用`CREATEUSER`指令。下面是一个根本的示例,展现了怎么创立一个新...

-
大数据资料,大数据年代下的机会与应战
大数据是指规划巨大、类型杂乱多样的数据调集,这些数据量超出了传统数据库软件东西的处理才能,需求新的处理形式来增强决议计划...

-
oracle怎样用,Oracle数据库入门与根底操作攻略
1.装置Oracle数据库:下载Oracle数据库软件。运转装置程序,并依照提示完结装置。2....

-
大数据技术需求学什么,你需求把握的中心技术
1.编程言语:学习至少一种编程言语,如Python、Java或Scala。Python因为其简练性和丰厚的库支撑,是大...

-
怎样进入mysql数据库,怎么进入MySQL数据库
要进入MySQL数据库,您需求运用MySQL的客户端程序。以下是一般过程:1.翻开指令提示符或终端窗口。2.输入以下...

-
导入数据库, 挑选适宜的数据库办理体系(DBMS)
您好,我了解您或许需求将数据导入到数据库中。但请注意,因为我作为一个文本和代码生成的AI,我无法直接与数据库进行交互。不...

-
大数据品种,大数据的品种与分类
大数据一般能够分为以下几品种型:除了上述三种根本类型,大数据还能够依据来历和用处进行进一步分类,如:交际媒体数据:来自...

-
学术期刊数据库,学术期刊数据库在现代科研中的重要性
以下是几个首要的学术期刊数据库及其简介:1.万方数据常识服务渠道供给我国学术期刊数据库(COJ),录入8500...
