
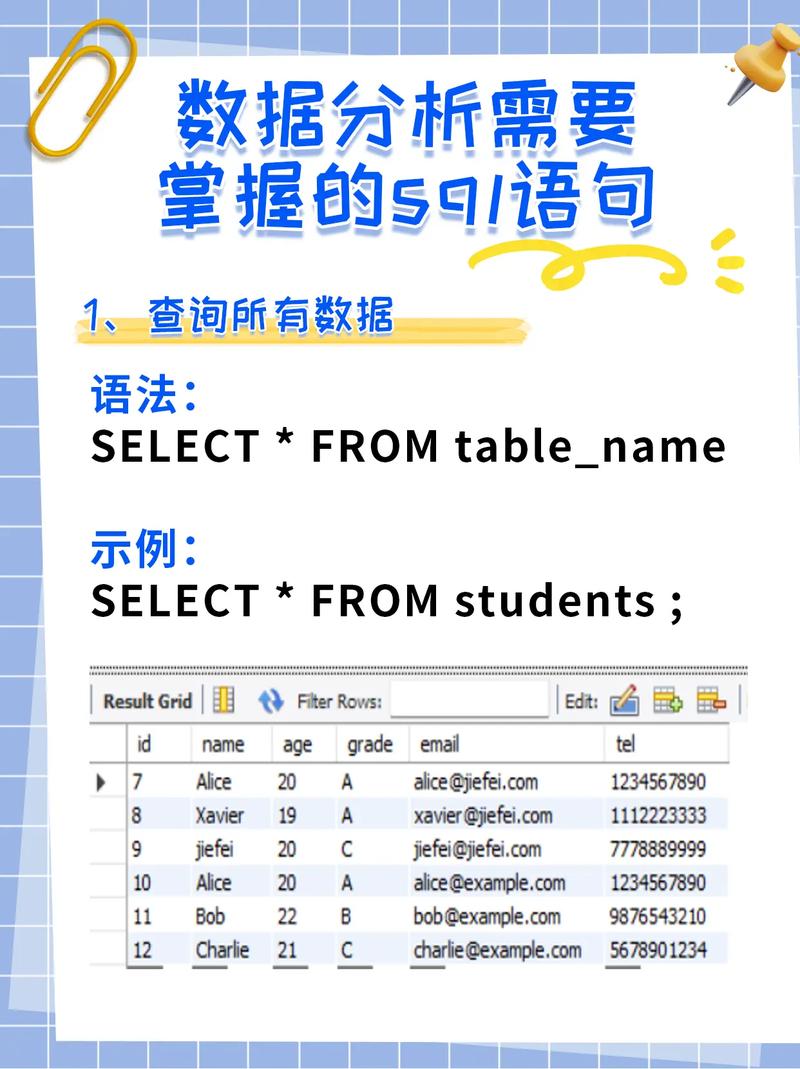
mysql查重,MySQL数据库中的数据查重办法详解
 admin
admin在MySQL中,查重一般指的是检查数据库中是否存在重复的记载。这能够经过多种办法完成,例如运用`UNION`、`GROUP BY`、`HAVING`、`COUNT`等SQL句子。下面是一些常见的查重办法:
1. 运用`UNION`: `UNION`能够用来兼并两个或多个SELECT句子的成果集,并主动去除重复的记载。 例如,假如你想要检查表`my_table`中`column1`列的重复值,能够运用以下SQL句子: ```sql SELECT column1 FROM my_table UNION SELECT column1 FROM my_table; ```
2. 运用`GROUP BY`和`HAVING`: `GROUP BY`能够将成果集依照指定的列进行分组。 `HAVING`能够用来过滤分组后的成果。 例如,假如你想要找出`my_table`表中`column1`列的重复值,能够运用以下SQL句子: ```sql SELECT column1, COUNT as count FROM my_table GROUP BY column1 HAVING count > 1; ```
3. 运用`COUNT`: `COUNT`函数能够用来计算成果会集的记载数。 例如,假如你想要检查`my_table`表中`column1`列的重复值,能够运用以下SQL句子: ```sql SELECT column1, COUNT as count FROM my_table GROUP BY column1 HAVING count > 1; ```
4. 运用`DISTINCT`: `DISTINCT`关键字能够用来回来仅有不同的值。 例如,假如你想要获取`my_table`表中`column1`列的仅有值,能够运用以下SQL句子: ```sql SELECT DISTINCT column1 FROM my_table; ```
5. 运用`EXISTS`: `EXISTS`能够用来检查子查询中是否存在任何记载。 例如,假如你想要检查`my_table`表中是否存在与`other_table`表中`column2`列相同的`column1`值,能够运用以下SQL句子: ```sql SELECT column1 FROM my_table WHERE EXISTS ; ```
这些办法能够依据你的详细需求挑选运用。假如你有更详细的需求或问题,请随时发问。
MySQL数据库中的数据查重办法详解
在数据库办理中,数据查重是一个常见且重要的使命。它有助于保证数据的仅有性和准确性,特别是在处理很多数据时。本文将详细介绍MySQL数据库中的数据查重办法,包含单字段查重、多字段查重以及一些高档查重技巧。
单字段查重

单字段查重是最基本的查重办法,一般用于检查某个字段中是否存在重复的值。以下是一个简略的单字段查重示例:
SELECT nickname, COUNT() as repeat_count
FROM user
GROUP BY nickname
HAVING COUNT() > 1;
在这个比如中,咱们查询了`user`表中的`nickname`字段,并运用`GROUP BY`和`HAVING`子句来找出重复的昵称。
多字段查重
多字段查重用于检查多个字段组合的值是否重复。这种办法在处理复合键时十分有用。以下是一个多字段查重的示例:
SELECT nickname, email, COUNT() as repeat_count
FROM user
GROUP BY nickname, email
HAVING COUNT() > 1;
在这个比如中,咱们一起检查了`nickname`和`email`字段的组合是否重复。
运用DISTINCT去重

MySQL的`DISTINCT`关键字能够用来直接去除查询成果中的重复行。以下是一个运用`DISTINCT`的示例:
SELECT DISTINCT nickname
FROM user;
这个查询将回来`user`表中所有仅有的昵称。
运用子查询进行查重
子查询是进行杂乱查重操作的一种强壮东西。以下是一个运用子查询来删去重复记载的示例:
DELETE t1 FROM user AS t1
INNER JOIN (
SELECT nickname, MIN(id) as min_id
FROM user
GROUP BY nickname
HAVING COUNT() > 1
) AS t2 ON t1.nickname = t2.nickname AND t1.id > t2.min_id;
在这个比如中,咱们首要创建了一个子查询来找出每个昵称的最小`id`值,然后运用这个成果来删去那些`id`大于最小`id`的记载,然后保存每个昵称下`id`最小的记载。
运用暂时表进行查重

在某些情况下,运用暂时表能够协助咱们更有效地进行查重操作。以下是一个运用暂时表的示例:
CREATE TEMPORARY TABLE temp_user AS
SELECT nickname, COUNT() as repeat_count
FROM user
GROUP BY nickname
HAVING COUNT() > 1;
SELECT FROM temp_user;
在这个比如中,咱们首要创建了一个暂时表`temp_user`来存储重复的昵称及其重复次数,然后查询这个暂时表来检查重复的昵称。
MySQL供给了多种办法来进行数据查重,从简略的单字段查重到杂乱的多字段组合查重。挑选适宜的办法取决于详细的使用场景和数据结构。经过合理运用这些办法,能够有效地保证数据库中数据的仅有性和准确性。
MySQL, 数据库, 查重, 单字段, 多字段, DISTINCT, 子查询, 暂时表
相关文章
-
mysql类型转化函数,二、类型转化函数概述
1.`CAST`函数:将一个值转化为指定的数据类型。例如,将字符串转化为数字。```sqlSELECT...

-
期刊数据库有哪些,资源类型与常用渠道介绍
1.我国知网(CNKI):我国最大的学术资源库,包含很多的中文期刊、学位论文、会议论文等。2.万方数据:供给包含期刊...

-
数据库引擎有哪些, 联系型数据库引擎概述
1.InnoDB:这是MySQL数据库中的一个事务型存储引擎,它支撑事务处理、行级确定和外键束缚。InnoDB由MyS...

-
mysql中varchar最大长度,二、VARCHAR数据类型概述
MySQL中`VARCHAR`类型最大长度取决于所运用的MySQL版别:在MySQL5.0及之前版别,`VARCHA...

-
中国移动大数据,驱动数字化转型的新引擎
中国移动的大数据事务主要由其“梧桐大数据”途径承载,包括了从数据接入到使用发布的全流程服务。以下是关于中国移动大数据的详...

-
大数据预处理,大数据预处理的重要性
大数据预处理是大数据剖析和发掘之前的重要进程,其意图是进步数据质量,保证后续剖析的有效性和准确性。预处理包含多个方面,如...

-
怎样备份数据库,数据库备份的重要性与施行进程
备份数据库是维护数据免受意外丢掉或损坏的重要进程。以下是备份数据库的一些根本进程,适用于大多数数据库体系,如MySQL、...
-
生态环境大数据,推进绿色开展的才智引擎
生态环境大数据是指使用大数据技能,对生态环境范畴的各类数据进行收集、存储、剖析和使用,以进步生态环境办理才能和决议计划水...