
机器学习算法陈腔滥调,面试必备知识点解析
 admin
admin机器学习算法陈腔滥调是指将机器学习算法的原理和使用以固定的格局进行论述,这种格局一般包含算法的布景、原理、使用场景、优缺点等方面。这种陈腔滥调式的论述方法可以协助人们快速了解机器学习算法的基本情况,但在实践使用中,需求依据具体问题挑选适宜的算法,并进行相应的调整和优化。
1. 决策树:决策树是一种常用的分类和回归算法,经过构建一棵树形结构来对数据进行分类或回归猜测。决策树的长处是易于了解和完成,但简略过拟合,需求进行剪枝等处理。
2. 支撑向量机(SVM):SVM是一种用于二分类问题的算法,经过寻觅一个超平面来将不同类其他数据分隔。SVM的长处是可以处理高维数据,对噪声和异常值不灵敏,但需求挑选适宜的核函数和参数。
3. 随机森林:随机森林是一种集成学习算法,经过构建多棵决策树并进行投票来进步分类或回归的准确性。随机森林的长处是可以处理高维数据,对噪声和异常值不灵敏,但核算杂乱度较高。
4. 聚类算法:聚类算法是一种无监督学习算法,经过将数据分为若干个类别来发现数据中的潜在结构。常见的聚类算法有Kmeans、层次聚类等。聚类算法的长处是可以发现数据中的潜在结构,但需求挑选适宜的聚类数目和算法参数。
5. 神经网络:神经网络是一种模仿人脑神经元结构的算法,经过多层神经元之间的连接来对数据进行分类或回归猜测。神经网络的长处是可以处理杂乱的非线性联系,但需求很多的数据和核算资源进行练习。
以上仅仅一些常见的机器学习算法陈腔滥调,实践上机器学习算法的品种非常丰富,需求依据具体问题挑选适宜的算法,并进行相应的调整和优化。
机器学习算法陈腔滥调:面试必备知识点解析

在机器学习范畴,面试官常常会针对一些常见的算法进行发问,这些被称为“陈腔滥调”的知识点。把握这些知识点关于求职者来说至关重要。本文将为您解析机器学习算法陈腔滥调,协助您在面试中锋芒毕露。
一、监督学习算法
监督学习算法是机器学习中最根底的一类算法,首要包含以下几种:
1. 线性回归
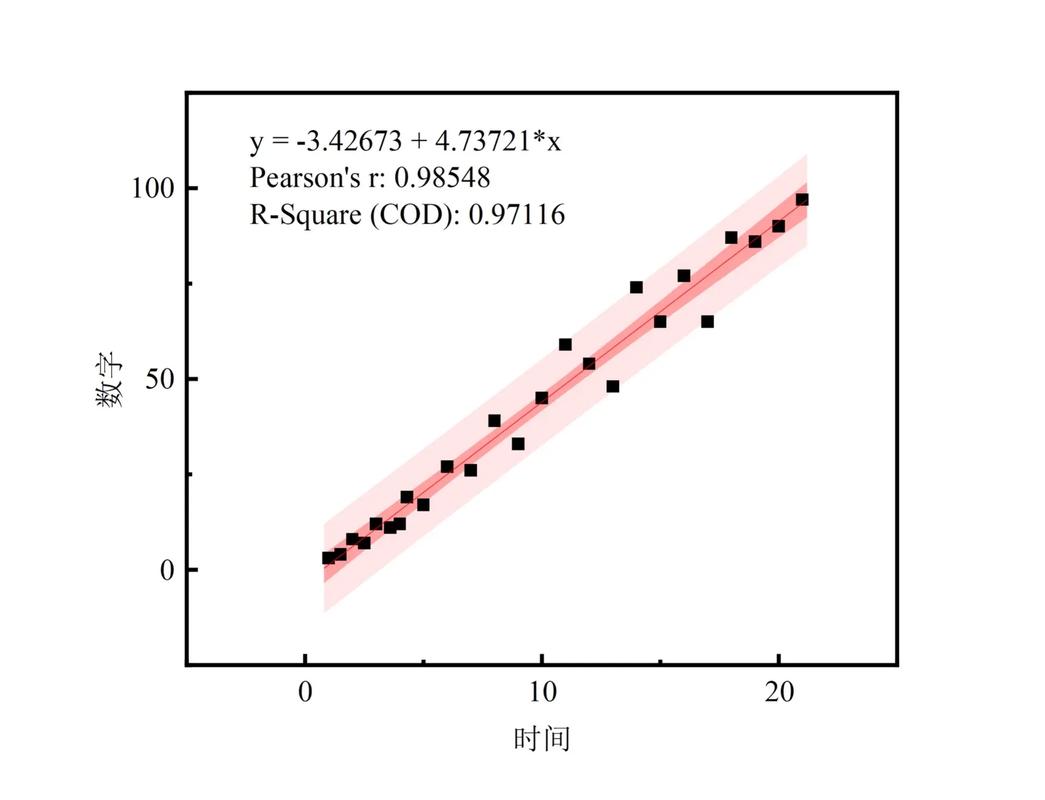
线性回归是一种简略的猜测模型,经过拟合数据点与目标值之间的线性联系来进行猜测。其中心思维是最小化猜测值与实践值之间的差错平方和。
2. 逻辑回归
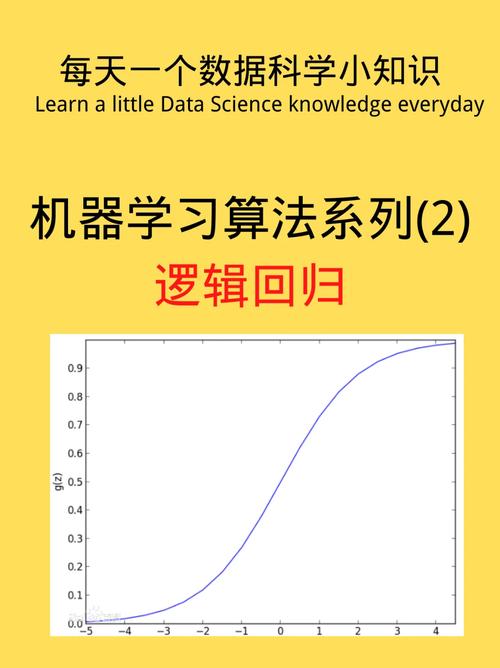
逻辑回归是一种二分类模型,经过求解逻辑函数来猜测样本归于正类或负类的概率。它常用于处理分类问题,如垃圾邮件检测、情感剖析等。
3. 决策树
决策树是一种依据树结构的分类算法,经过递归地将数据集划分为若干个子集,并挑选最优的特征进行切割,终究构成一棵树。决策树具有直观易懂、易于解说的特色。
4. 支撑向量机(SVM)

支撑向量机是一种二分类模型,经过寻觅最优的超平面将数据集划分为两个类别。SVM具有较好的泛化才能,在图像识别、文本分类等范畴有广泛使用。
5. K最近邻(KNN)
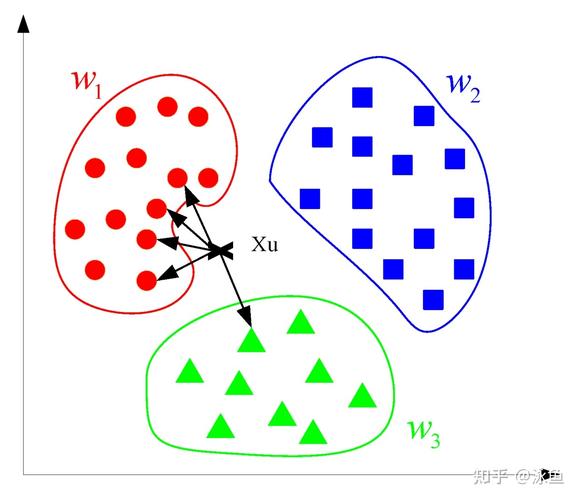
K最近邻算法是一种依据间隔的简略分类算法,经过核算待分类样本与练习会集每个样本的间隔,选取间隔最近的K个样本,并依据这K个样本的类别进行猜测。
二、无监督学习算法

无监督学习算法首要用于处理非标记数据,首要包含以下几种:
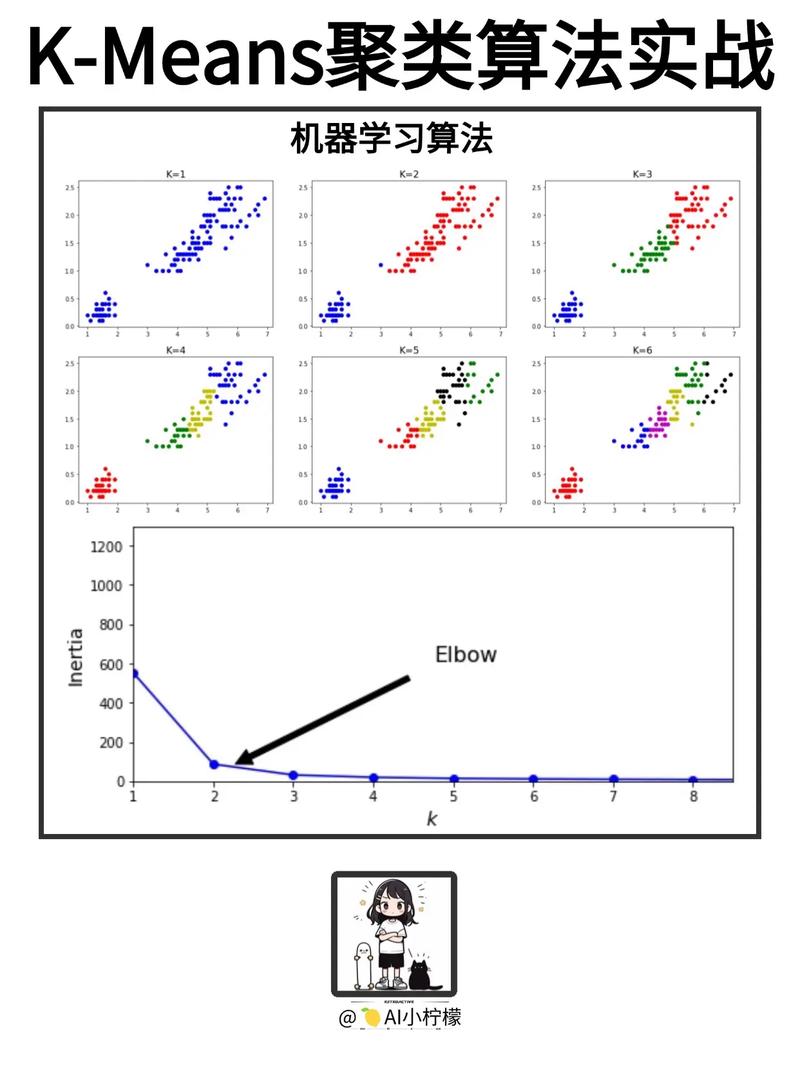
1. K-means聚类

K-means聚类是一种依据间隔的聚类算法,经过迭代优化聚类中心,将数据集划分为K个簇,使得每个簇内的样本间隔聚类中心较小,而不同簇之间的样本间隔较大。
2. 主成分剖析(PCA)
主成分剖析是一种降维算法,经过将原始数据投影到低维空间,保存数据的首要信息,然后下降核算杂乱度。
3. 聚类层次法
聚类层次法是一种依据层次结构的聚类算法,经过兼并间隔最近的两个簇,逐步构成一棵树,终究得到聚类成果。
4. 聚类EM算法

聚类EM算法是一种依据概率模型的聚类算法,经过迭代优化模型参数,将数据集划分为多个簇,使得每个簇内的样本概率较大,而不同簇之间的样本概率较小。
三、强化学习算法

强化学习是一种经过与环境交互来学习最优战略的算法,首要包含以下几种:
1. Q学习
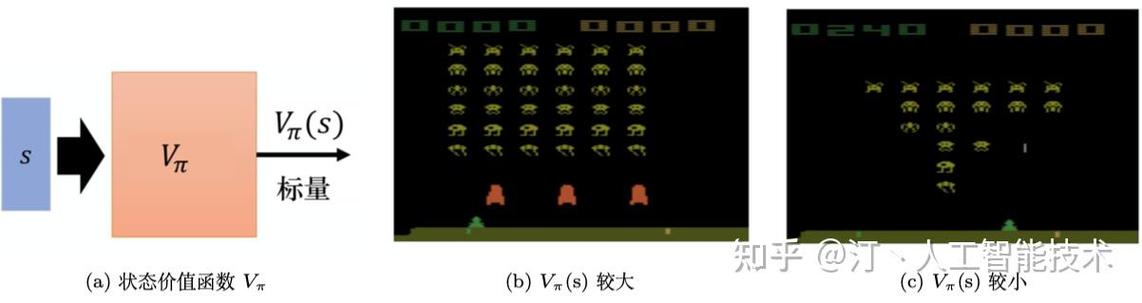
Q学习是一种依据值函数的强化学习算法,经过学习状况-动作值函数,挑选最优的动作来最大化长时间奖赏。
2. 战略梯度法
战略梯度法是一种依据战略的强化学习算法,经过直接优化战略函数,挑选最优的动作来最大化长时间奖赏。
3. 深度Q网络(DQN)
深度Q网络是一种结合了深度学习和Q学习的强化学习算法,经过神经网络来近似Q函数,然后完成更杂乱的战略学习。
把握机器学习算法陈腔滥调关于求职者来说至关重要。本文为您解析了监督学习、无监督学习和强化学习中的常见算法,期望对您的面试有所协助。
相关文章
-
机器学习,界说与概述
机器学习(MachineLearning)是人工智能的一个分支,它使核算机体系可以从数据中学习并改善其功能,而无需清晰...

-
ai归纳使用,推进工业革新与立异开展的新引擎
AI归纳使用是指将人工智能技能使用于各个范畴,以处理实际问题并进步功率。以下是几个AI归纳使用范畴的比如:1.医疗健康...

-
AI写ppt,高效与构思的完美结合
当然能够!我能够协助你编撰PPT的内容。请告诉我你需求关于什么主题的PPT,以及你期望绵亘哪些详细信息或要害。我会依据你...

-
股票猜测机器学习,技能革新与未来展望
股票猜测是一个杂乱的问题,由于它涉及到很多的变量和不确定性。机器学习能够供给一种办法来剖析前史数据,并从中提取有用的形式...

-
斯坦福机器学习证书,在线学习,成果未来
假如你想取得斯坦福大学的机器学习证书,能够经过Coursera渠道上的“机器学习专项课程”来完结。这个课程由斯坦福大学和...

-
ai归纳原料画,探究数字艺术的新境地
1.AIACG绘画网站:这是一个完全免费的AI绘画网站,供给了很多的AI绘画模型,绵亘二次元、插画和美人大模型,...

-
机器学习模型怎样跑,从建立到优化
机器学习模型一般绵亘以下几个进程来运转:1.数据预备:首要需求搜集和预备数据,这绵亘数据清洗、数据转化和数据归一化等。...

-
amd做机器学习,AMD在机器学习范畴的立异与打破
1.AMDRyzenAI软件:RyzenAI软件:这款软件可以协助用户在AIPC上轻松构建和布置机...
