
机器学习 数据集,机器学习数据集的重要性
 admin
admin数据集能够分为以下几种类型:
4. 强化学习数据集:这种数据集包含一系列状况、动作和奖赏,用于练习强化学习模型。强化学习模型的方针是学习一个战略,以最大化累积奖赏。
在挑选和运用数据集时,需求考虑以下要素:
1. 数据集的巨细:数据集的巨细关于模型的功能至关重要。一般来说,数据集越大,模型的功能越好。
2. 数据集的质量:数据集的质量关于模型的功能也非常重要。数据会集的噪声、异常值和不一致性都会影响模型的功能。
3. 数据集的多样性:数据集的多样性关于模型的泛化才能至关重要。模型需求能够在未见过的数据上体现出杰出的功能。
4. 数据集的平衡性:数据集的平衡性关于模型的功能也很重要。假如数据会集的某些类别或特征被过度代表,模型或许会对这些类别或特征发生成见。
总归,挑选和运用适宜的数据集关于机器学习模型的功能至关重要。需求依据具体使命和数据集的特色,挑选适宜的模型和算法,并进行恰当的练习和调优。
机器学习数据集的重要性
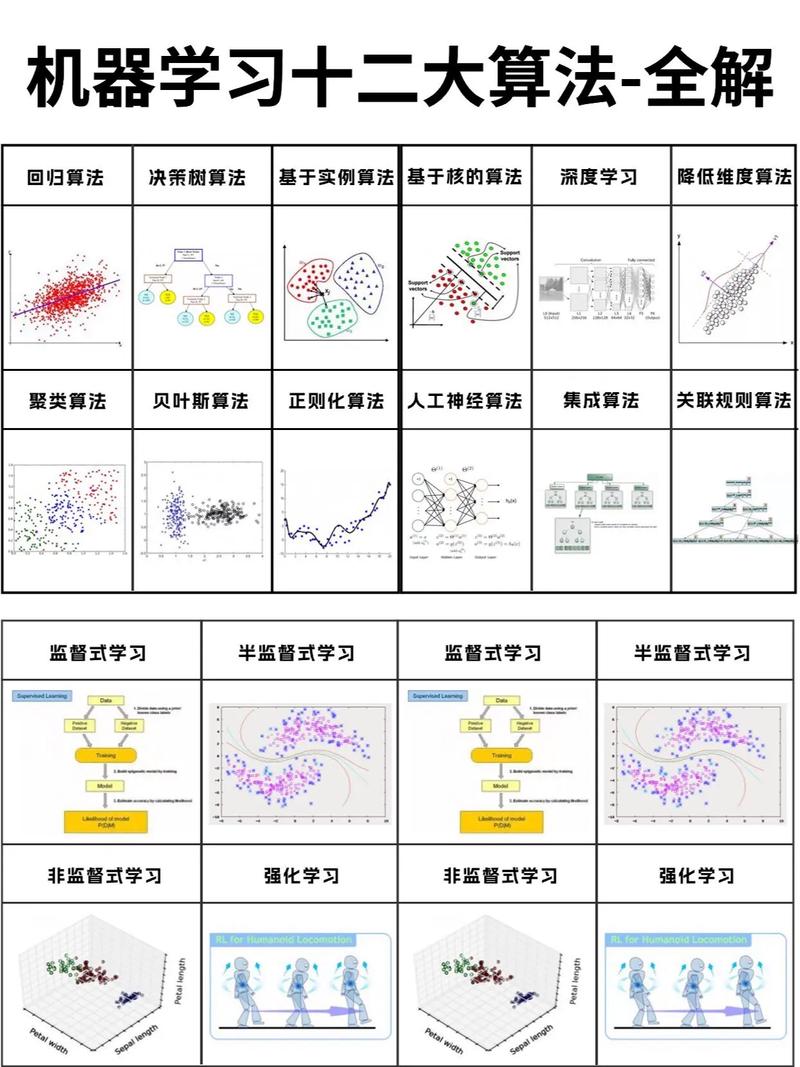
在机器学习范畴,数据集是构建和练习模型的根底。一个高质量的数据集关于模型的准确性和可靠性至关重要。本文将讨论机器学习数据集的重要性、类型以及怎么挑选适宜的数据集。
数据集在机器学习中的效果

数据集是机器学习模型的“食物”。没有满足的数据,模型就无法学习到有用的特征和形式。以下是数据集在机器学习中的几个关键效果:
特征学习:数据集供给了模型学习到的特征,这些特征将用于猜测或分类使命。
形式识别:经过剖析数据集,模型能够识别出数据中的形式和规则。
模型评价:数据集能够用于评价模型的功能,包含准确率、召回率、F1分数等目标。
泛化才能:一个高质量的数据集能够协助模型在不知道数据上体现杰出,即泛化才能。
数据集的类型

依据数据集的来历和用处,能够分为以下几种类型:
半监督学习数据集:包含部分符号和部分未符号的数据,用于练习半监督学习模型。
强化学习数据集:一般不直接供给数据集,而是经过与环境交互来学习战略。
挑选适宜的数据集
数据质量:保证数据集洁净、无噪声、无缺失值。
数据多样性:数据集应包含满足多的样本和特征,以掩盖不同的场景。
数据散布:数据集应具有合理的散布,以防止模型在特定子集上过拟合。
数据规划:依据项目需求挑选适宜的数据规划,过大或过小都或许影响模型功能。
数据集的获取与处理
揭露数据集:许多安排和研究机构供给揭露的数据集,如UCI机器学习库、Kaggle等。
数据发掘:从现有数据源中提取数据,如数据库、日志文件等。
数据搜集:经过问卷调查、传感器、网络爬虫等办法搜集数据。
获取数据后,需求进行数据预处理,包含以下过程:
数据清洗:去除噪声、缺失值、异常值等。
数据转化:将数据转化为适宜模型输入的格局。
特征工程:创立新的特征或转化现有特征,以进步模型功能。
数据集的评价与优化
穿插验证:经过将数据集划分为练习集和验证集,评价模型在不同数据子集上的功能。
特征挑选:挑选对模型功能影响最大的特征,以削减过拟合和提高功率。
数据增强:经过添加噪声、旋转、缩放等操作,添加数据集的多样性。
定论

数据集是机器学习项目的柱石,挑选适宜的数据集关于模型的成功至关重要。本文介绍了数据集在机器学习中的效果、类型、获取途径以及评价和优化办法。经过深化了解数据集,能够更好地构建和练习机器学习模型,为实践使用供给有力支撑。
机器学习 数据集 数据预处理 数据质量 特征工程 模型评价
相关文章
-
ai识图,革新视觉辨认的未来
1.图画分类:将图画分类到不同的类别中,例如辨认图画中的物体、场景、情感等。2.方针检测:在图画中检测并定位特定的物...

-
巴黎归纳理工ai,AI范畴的前锋力气
巴黎归纳理工学院:AI范畴的前锋力气巴黎归纳理工学院(EcolePolytechnique),简称X,作为法国甚至欧洲...

-
ai se 归纳,推进工业革新与立异
AISE(AIforSoftwareEngineering,人工智能辅佐软件工程)是指将人工智能技能运用于软件工...

-
机器学习大牛,那些改动世界的“大牛”们
1.MichaelI.Jordan:他是加州大学伯克利分校的教授,担任计算人工智能试验室(SAIL)主任和...

-
机器学习的进程,机器学习进程概述
机器学习是一个迭代的进程,它包含以下首要进程:1.界说问题:明晰你要处理的问题是什么。这包含确认方针变量(猜测或分类的...

-
ai资料,立异内容创造的得力助手
1.爱给网供给多种格局的矢量图资料,包含AI、EPS、CDR、SVG等,适用于平面规划、UI、海报、PPT等砛...

-
机器学习程序,从入门到实践
当然,我可以协助你了解机器学习程序的基本概念。机器学习是一种人工智能技能,它答应核算机从数据中学习并做出决议计划或猜测,...

-
机器学习与大数据实战,从理论到使用的跨过
机器学习与大数据实战是当今科技范畴中十分抢手的两个方向。它们彼此相关,相得益彰,一起推进着各行各业的智能化转型。以下是对...
