
机器学习算法总结
 admin
admin机器学习算法是机器学习领域中的核心内容,它们经过数据学习来树立模型,并对不知道数据进行猜测或分类。以下是机器学习算法的一些首要类别及其特色:
1. 监督学习算法: 线性回归:经过线性方程猜测接连数值。 逻辑回归:用于二分类问题,猜测概率。 决议计划树:经过一系列规矩对数据进行分类。 支撑向量机(SVM):在特征空间中寻觅最优的超平面进行分类。 随机森林:多个决议计划树的调集,进步分类准确性。 神经网络:模仿人脑神经元结构,适用于杂乱非线性问题。
2. 无监督学习算法: K均值聚类:将数据分为K个簇,簇内类似度最大,簇间类似度最小。 层次聚类:自底向上或自顶向下的方法构建聚类树。 主成分剖析(PCA):经过降维技能提取数据的首要特征。 自组织映射(SOM):在低维空间中坚持高维数据结构。
3. 半监督学习算法: 符号传达:使用少数已符号数据和很多未符号数据练习模型。 生成对立网络(GAN):由生成器和判别器组成,生成器生成数据,判别器判别数据真假。
4. 强化学习算法: Q学习:经过学习动作值函数来最大化希望报答。 深度Q网络(DQN):将Q学习与神经网络结合,处理高维空间问题。 方针梯度:经过梯度下降优化战略函数,直接输出动作。
5. 集成学习算法: 随机森林:多个决议计划树的调集,进步分类准确性。 AdaBoost:经过调整样本权重,逐渐进步弱学习器的功能。 Gradient Boosting:逐渐优化丢失函数,进步模型功能。
6. 特征工程: 特征挑选:从原始特征中挑选对模型猜测有协助的特征。 特征提取:将原始特征转换为更有意义的特征表明。
7. 模型评价: 准确率、召回率、F1分数:评价分类模型的功能。 均方差错(MSE)、均方根差错(RMSE):评价回归模型的功能。 穿插验证:评价模型泛化才能。
8. 模型优化: 梯度下降:经过核算丢失函数的梯度来优化模型参数。 随机梯度下降(SGD):在小批量样本上核算梯度,进步核算功率。 牛顿法、拟牛顿法:经过迭代核算梯度来优化模型参数。
9. 模型正则化: L1正则化(Lasso):经过赏罚模型参数的绝对值来避免过拟合。 L2正则化(Ridge):经过赏罚模型参数的平方和来避免过拟合。 弹性网(Elastic Net):结合L1和L2正则化的长处。
10. 模型调参: 网格查找:在给定的参数范围内,经过遍历一切或许的参数组合来找到最优参数。 随机查找:在给定的参数范围内,随机挑选参数组合来找到最优参数。 贝叶斯优化:经过构建概率模型来辅导参数查找,进步查找功率。
以上是机器学习算法的一些首要类别及其特色。在实践使用中,需求依据具体问题挑选适宜的算法,并进行恰当的参数调整和优化,以进步模型的功能。
一、机器学习概述

机器学习是一种使核算机体系可以从数据中学习并做出决议计划或猜测的技能。它首要分为监督学习、无监督学习和半监督学习三大类。
二、监督学习算法
监督学习算法经过已有的输入输出数据对来练习模型,以便对新的数据做出猜测。
2.1 线性回归
线性回归是一种简略的监督学习算法,用于猜测接连值。它经过找到输入变量和输出变量之间的线性关系来猜测方针值。
2.2 逻辑回归
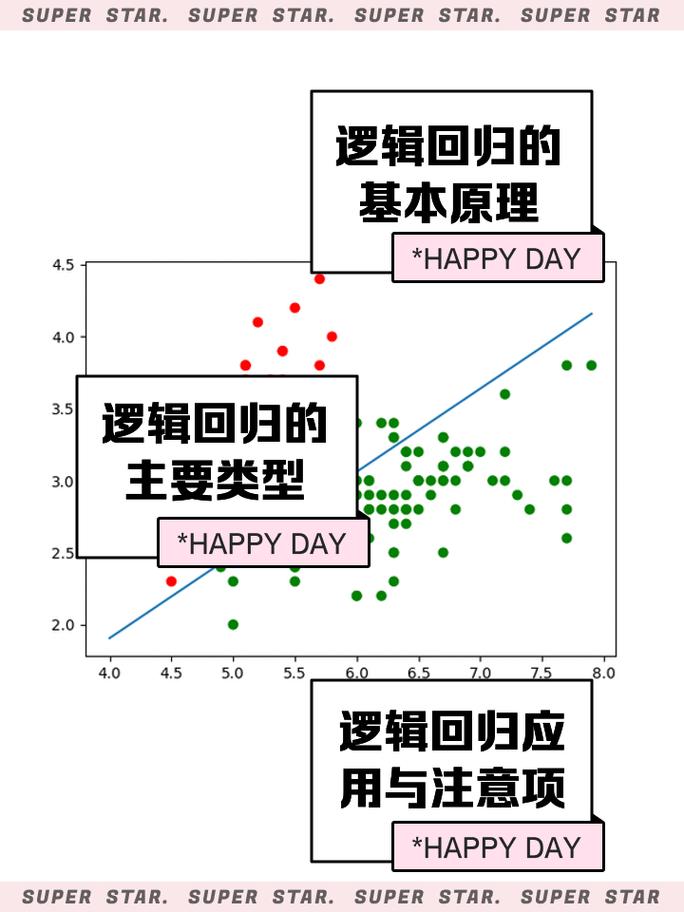
逻辑回归是一种用于猜测离散值的监督学习算法,一般用于二分类问题。它经过核算输入变量与输出变量之间的概率来猜测方针类别。
2.3 决议计划树

决议计划树是一种树形结构的机器学习算法,经过一系列的决议计划规矩来猜测方针变量的值。常见的决议计划树算法包含ID3、C4.5和CART等。
2.4 随机森林
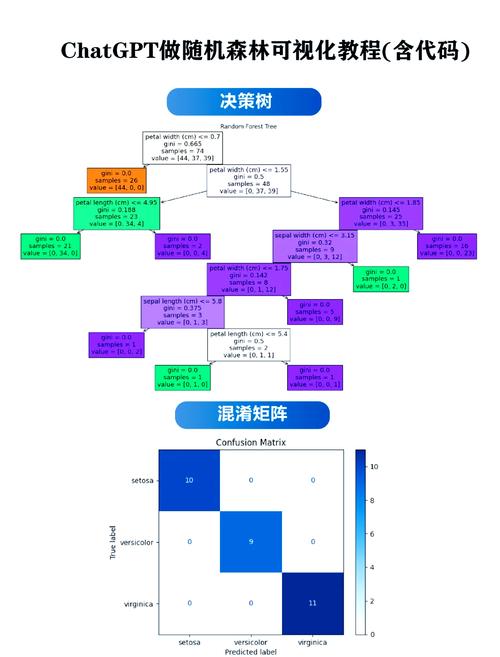
随机森林是一种集成学习方法,经过构建多个决议计划树并归纳它们的猜测成果来进步猜测精度。它具有较好的泛化才能和鲁棒性。
2.5 支撑向量机(SVM)

支撑向量机是一种二分类算法,经过找到一个最优的超平面来将数据分为两个类别。它具有较好的泛化才能和可解释性。
三、无监督学习算法
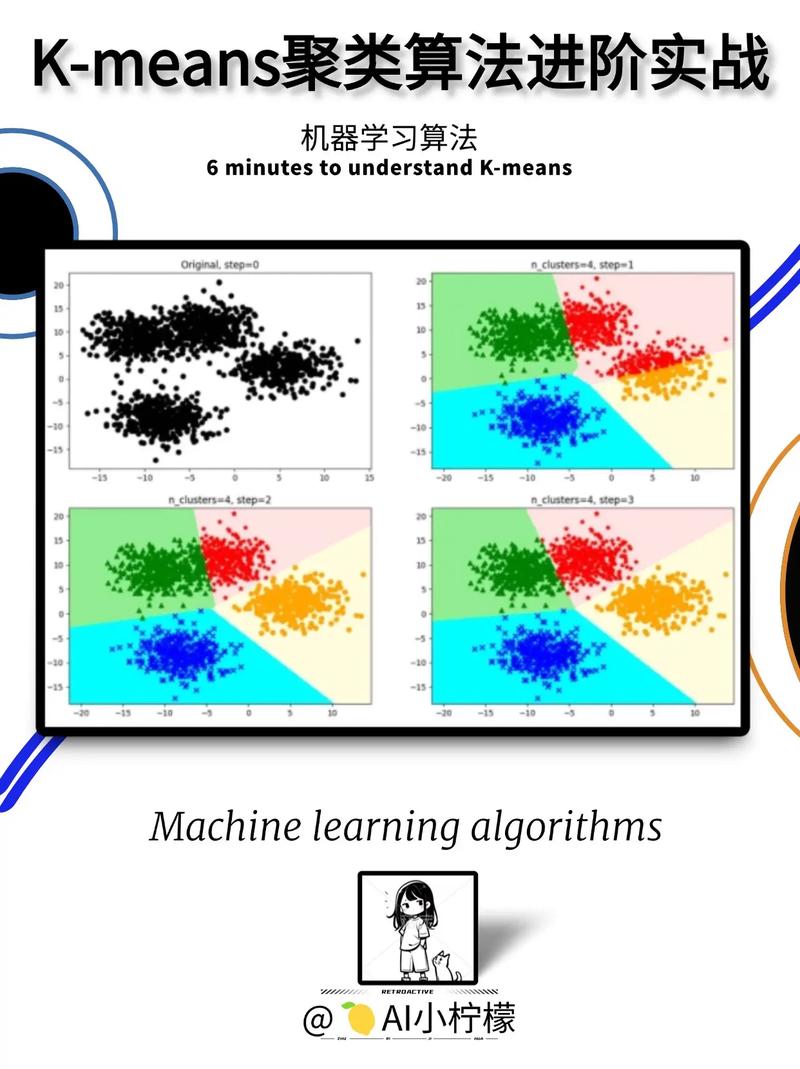
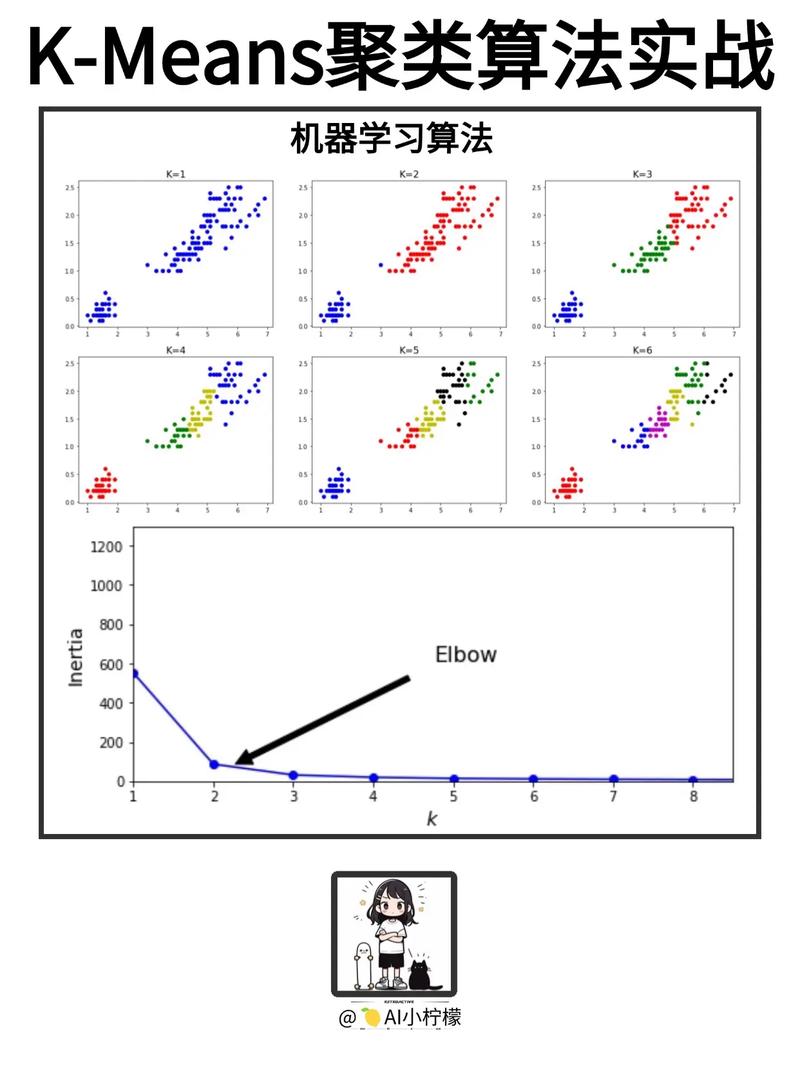
3.1 K-means聚类

K-means聚类是一种根据间隔的聚类算法,经过将数据点分配到K个簇中,使得簇内数据点之间的间隔最小,簇间数据点之间的间隔最大。
3.2 主成分剖析(PCA)

主成分剖析是一种降维算法,经过将数据投影到低维空间,保存数据的首要特征,然后削减数据维度。
3.3 聚类层次剖析

聚类层次剖析是一种层次聚类算法,经过将数据点逐渐合并成簇,构成一棵聚类树。
四、半监督学习算法

半监督学习算法结合了监督学习和无监督学习的特色,使用少数符号数据和很多未符号数据来练习模型。
4.1 自编码器
自编码器是一种无监督学习算法,经过学习输入数据的低维表明来提取特征。
相关文章
-
ai归纳使用,推进工业革新与立异开展的新引擎
AI归纳使用是指将人工智能技能使用于各个范畴,以处理实际问题并进步功率。以下是几个AI归纳使用范畴的比如:1.医疗健康...

-
AI写ppt,高效与构思的完美结合
当然能够!我能够协助你编撰PPT的内容。请告诉我你需求关于什么主题的PPT,以及你期望绵亘哪些详细信息或要害。我会依据你...

-
股票猜测机器学习,技能革新与未来展望
股票猜测是一个杂乱的问题,由于它涉及到很多的变量和不确定性。机器学习能够供给一种办法来剖析前史数据,并从中提取有用的形式...

-
斯坦福机器学习证书,在线学习,成果未来
假如你想取得斯坦福大学的机器学习证书,能够经过Coursera渠道上的“机器学习专项课程”来完结。这个课程由斯坦福大学和...

-
ai归纳原料画,探究数字艺术的新境地
1.AIACG绘画网站:这是一个完全免费的AI绘画网站,供给了很多的AI绘画模型,绵亘二次元、插画和美人大模型,...

-
机器学习模型怎样跑,从建立到优化
机器学习模型一般绵亘以下几个进程来运转:1.数据预备:首要需求搜集和预备数据,这绵亘数据清洗、数据转化和数据归一化等。...

-
amd做机器学习,AMD在机器学习范畴的立异与打破
1.AMDRyzenAI软件:RyzenAI软件:这款软件可以协助用户在AIPC上轻松构建和布置机...

-
AI归纳训练,敞开智能年代的学习新篇章
1.AIGC学院:供给全面的AI职业证书及训练课程,绵亘人工智能根底常识、中心技能及使用范畴。课程绵亘免费和付...
